- General Information
- Designing your SQL Database
- In Depth
- Other Information
- Can't find what you're looking for?
Introduction (essential
reading when converting from TPS to SQL)
Using SQL with Clarion is not difficult, but there are
some things to know before you start. If you have no SQL experience, then
it is advised that you start with some basic tutorials to get yourself a
little more familiar with SQL. In terms of using SQL with Clarion, there
are often some mindsets that might need to be broken, as Clarion can be
very forgiving in terms of database design and implementation with
Flat-File systems such as TPS. Once you are familiar with some of these
concepts, implementing SQL in Clarion is not difficult. FM3 does
everything it can to make the conversion process as quick and easy as
possible. There are however some added things to know when using FM3, as
it sometimes needs a little more information from you regarding the
backend it is working with. All these things are discussed below.
File formats / databases:
Firstly, it is important to understand some of the fundamental differences
between using an SQL backend as oppose to a Flat-File format.
Flat-files
- TopSpeed
- Clarion
- Btrieve*
Client - Server
- Btrieve*
- SoftVelocity’sIP Driver
This is essentially a layer on top of flat files. Server handles /
controls access to the files.
SQL / Relation Database Management System (RDMS)
- MsSQL
- Oracle
- FireBird
- MySQL
- PostgresSQL
- PervasiveSQL*
- Sybase
This is essentially a layer on top of Client-Server. Data access and
manipulation is done using Structured Query Language (SQL). SQL Databases
are generally described as relational database management systems.
* The Btrieve driver can be Client Server or Flat File. Pervasive have
also built an SQL layer to this file format.
Choosing your Database / File Driver:
Currently, we only discuss the pros and cons of Supported File Drivers and
Databases in FM3.
| Driver |
Pros |
Cons |
| BTrieve |
Free |
Limited to a 4K record size, Does not return helpful error
information for FM3. |
| Clarion |
|
Prone to corrupt, unbuilt keys and data files. |
| Topspeed |
Free, Good Performance |
Prone to corrupt files. |
| MsSQL |
Good performance, Stored Procedures and Triggers, Good name,
Tried and tested |
Fairly Expensive, Regular security patches |
| Oracle |
Good performance, Stored Procedures and Triggers, Good name |
Very Expensive, Needs a qualified DBA, i.e. a bit difficult for
the untrained to manage. |
| MySQL |
Good performance |
Not Free |
| Firebird |
Good Performance, Optionally Embedded, Stored Procedures and
Triggers, Free |
Key size limitation of 254K under default characterset, Keys
cannot have mixed sort orders, but this can be easily worked
around. |
| Sybase/ASA |
Good performance, Stored Procedures and Triggers, Good name,
Tried and tested |
Fairly Expensive (although cheaper than MSS) |
| PostgreSQL |
Good performance, Stored Procedures and Triggers, Free |
Text based variables don't handle non-printable characters.
Requires binary strings to be set to BINARY in the dct. |
Clarion / SQL Fundamentals
(essential reading when converting from TPS to
SQL)
Questions to ask before you start:
Who is Master?
The Clarion Dictionary
or
SQL Database Backend
The very idea of File Manager 3 implies that the Clarion Dictionary is the
master of the backend structure. In other words, you make changes in the
dictionary, and FM3 makes the relevant changes to the backend. In SQL
circles this could be severely frowned upon, especially if there is an
existing database, and / or a DataBase Administrator. Read on for further
discussion on this...
Who is in charge of the Database backend?
You, the developer
or
Some DBA or other 3rd party
In some SQL environments, you the developer are not permitted to change
anything on the backend, especially without permission. If there is a
Database Administrator, or another person in charge, they are not going to
like the idea of FM3. In circumstances like this, it may not be the best
solution to use FM3.
Do I have an existing database?
Existing TPS
or
Existing SQL
If you have an existing TPS database, then you'll need to read the
documentation on
Converting TPS to SQL. If you
have an existing SQL database, and are applying FM3, then you may find
that FM3 will want to make some changes to the structure, even if nothing
has changed. To understand more of this, read the
Datatypes
section. The Clarion synchronizer / table import in the dictionary does
not necessarily pick the best matched datatypes for your app, and again,
treats the backend as master instead of the dictionary.
Am I converting from Flat-files (eg: TPS)?
Converting Existing Data
As mentioned above, FM3 makes this a breeze, however, you must follow the
instructions laid out in the
Converting to SQL
section.
Design
ALL tables must contain a PRIMARY Key!
Good design suggests each table must contain a unique record identifier,
commonly known as a primary key. This should ideally be a single field key
of integer type. You may choose to auto-increment this field, or set it at
insert time. However, nulls and zero should not be allowed. While it is
not illegal to use other datatypes as your primary key, a numeric datatype
often provides the fastest data access to the table. This is also helpful
when declaring relationships. It is also not illegal to use
multi-component keys as your primary key, but this can also be untidy and
slow things down. In other words, create a simple fast primary key, and
declare other indexes for all your other purposes. A Globally Unique
Identifier (GUID) is most often a string / char datatype, and while this
could be a primary key, it is recommended you rather declare it as a
separate unique key. This means relationships can still be declared on the
Primary Key of the parent table. If you are using CapeSoft's
Replicate, and indeed any other type of replication, you may
required to use a multi-component Primary key. For example: PK_Customers
key(CUS:Site,CUS:CustomerID).
Ensure all Primary, Unique, and Foreign keys are uniquely named
throughout the database.
Different flavors of SQL don't allow duplicate names for certain objects.
For example, TPS users may like to name all there primary keys
"PrimaryKey". This will fail in most SQL backends. A good naming
convention is to use the tablename, or the fieldnames as part of the
keyname, e.g.: PK_Customers, FK_Countries, LastNameKey etc. You could also
add the file prefix to the external name attribute to ensure uniqueness,
e.g.: CUS_LastNameKey.
Ensure that all object names do not use Reserved Keywords.
Be sure not to name your tables, fields, and keys with reserved SQL
keywords, such as "Date". If you are converting from an existing
Dictionary, then you can effectively get around this by using the Full
Path Name, and External Name attributes to declare non reserved names. A
good suggestion is to use your file prefix and an underscore, e.g.
"PRE_Date".
There's no such thing as "Exclude Empty
Keys" in SQL
You need to turn this dictionary key option off for all your unique keys.
This is good practice in flat-files as well.
This option in the dictionary editor is such a bad idea. Seriously. It
causes so much heartache when converting TPS data to SQL. In SQL
nullability is on the _field_ not the key. In tps, blank fields (no such
thing as null in TPS) are excluded from the key table (which is like a
separate file within the tps file). In SQL, there is no option to exclude
elements of a key from that key if they are blank or null. So nulls/blanks
are included in the key. If it is a single element key, then you can only
have one null and one blank (or zero - not the same as null in SQL) value
in a key.
So when you come to exporting your data into SQL, you need to either: Make
the key non-unique, or remove records that cause a duplicate key error
(preferably before exporting to SQL). The easiest way is to make the key
non-unique - as there are essentially (because of that confounded "Exclude
Empty Keys" switch in the dct) duplicates in the key - although these
"duplicates" were permitted in TPS.
In SQL case-sensitive sorting is on the Field level
In the clarion dct, case-sensitivity is defined in the key - but
(depending on the default collation of your SQL database) - sort orders
are on the field. This is called the field collation. In order to maintain
an efficient sort order (or to maintain uniqueness across a key that is
case sensitive) you need to tell FM3 which fields you need to collate in
case-sensitive order. See the
CaseSensitive
field user option in the main FM3 docs for details on how to do this.
Define Foreign Keys on Integer type fields.
If you have followed the recommendation for Primary Keys, then this should
fall into place nicely. Again, performance will take a hit if you use
character type data as your foreign key links. Also, this keeps it clean
and simple. For example, if you have a Customer table that relates to a
Countries table. Build it something like this:
Code example:
CLARION:
| Customers |
|
file,pre(CUS),driver('MSSQL') |
| PK_Customers |
|
key(CustomerID),primary,nocase |
| FK_Countries |
|
key(CountryID),nocase |
|
| record |
|
record |
| CustomerID |
|
|
long |
|
| CountryID |
|
|
long |
|
| LastName |
|
|
string(40) |
|
| FirstName |
|
|
string(60) |
|
| |
|
end |
|
|
| |
|
end |
|
| Countries |
|
file,pre(COU),driver('MSSQL') |
| PK_Countries |
|
key(CountryID),primary,nocase |
! Links to Customers
FK_Countries |
| record |
|
record |
| CountryID |
|
|
long |
|
| Country |
|
|
string(100) |
| |
|
end |
| |
|
end |
|
One of the biggest benefits of this style of design is that you should
never ever need to alter those fields - i.e., the primary and foreign key
fields. This means FM3 can easily and safely upgrade the files, even when
your relationships reside on an SQL backend. This also ensures data
integrity.
Recommendations and Tips
The Owner string
- Use a global variable for this attribute. In the dictionary, place
an exclamation mark in front of the variable name: e.g.: !GLO:dbOwner
- For FM3, use a String, not a CString for your owner variable.
- Use the FM3:Connect To SQL Backend
extension template for creating a connect procedure for priming your
owner variable.
The SQL Database
- You do not need to create the tables on the SQL backend. FM3 will do
this for you.
- You need to create the database on the SQL Backend, and setup a
user.
- The SQL User login must be the dbowner of the database (MsSQL).
You don't need to worry
about this next bit as it's now taken care of in the DLL - unless you
don't want your application to use a sysadmin login. If you don't want
your application to use SysAdmin rights, then you must create the linked
server manually, and then login with a user with dbOwner rights.
For complete automation of FM3 administration, the user should also be a
member of the SysAdmin role (MsSQL). This is, however, not necessary if
you can create the linkedserver manually as follows:
FM3 needs to perform administrative tasks on the SQL backend. It therefore
needs some level of administration rights. These rights can be limited to
dbowner by completing the following configuration of the MsSQL Server. Two
tasks must be completed on your MsSQL Server for FM3 to continue it's job.
The server must be a linked server, and the server option DATA ACCESS must
be set to true.
To Add the MsSQL Server as a Linked Server
- From your SQL Query Analyser, execute this script:
EXEC sp_addlinkedserver
'<YourSQLServerName>','SQL Server' where
<YourSQLServerName> is the name of your SQL Server.
- For more information, see the Microsoft SQL Server Books Online.
To set the DATA ACCESS option to TRUE
- From your SQL Query Analyser, execute this script:
EXEC sp_serveroption
'<YourSQLServerName>', 'DATA ACCESS', 'TRUE' where
<YourSQLServerName> is the name of your SQL Server.
- For more information, see the Microsoft SQL Server Books Online.
SQL Data Types
(essential reading when converting from TPS to
SQL)
Dates and Times
Memos
Reals
Arrays (Dimensioned fields)
Dynamic and Static Indexes
Oracle DataType
Matching
Large String Data
MSSQL - UniqueIdentifier
Binary strings (see the
PostgreSQL section of the docs)
Computed fields
Dates and Times
Did You Know?
Some of the SQL drivers DO NOT directly support the DATE and TIME
datatypes in Clarion. In some drivers DATE may be used, but there are some
things to watch out for and think about when using DATEs and TIMEs.
Note: Sybase (ASA), PostgreSQL, Firebird,
MSSQL 2008
do support the native DATE and TIME
datatypes, so you won't need to follow the below mentioned suggestions.
Also MSSQL 2005 allows a DATE to be mapped directly to a datetime (and
likewise a time) - so you can use those as is.
What to do:
Here are 4 options for Dates and Times. The bottom line is there are pros
and cons to all the options! FM3 supports all 4 options. These points are
provided for your information to help you make the best design choice for
your scenario!
Option 1: Use a GROUP over STRING(8) containing a DATE field and a
TIME field (only required for MySQL, Oracle and MSSQL users ).
MSSQL users: You'll only need to use this option if you find yourself in
one (or more) of the following situations:
- Using MSSQL 2000 or previous.
- Your Date and/or time is part of a unique key (or your TIME is part
of any index).
- You have other applications (probably non-Clarion) using the
database that require a datetime (with both portions populated).
This is the default import behaviour for most SQL date datatypes into a
Clarion dictionary. This is all very well, but nasty if you're converting
an existing app to SQL. Apart from going and updating all the structures
in the dictionary, you'll have to make changes to your code within the
program to handle the new structure, and process the data as required.
Though you can still set up individual date or time key, a date+time key
will not be possible! The up side is that by using the standard backend
date, other apps will also be able to use the same info. The fact of the
matter: if you have to build an app for an existing database with existing
data, you're going to have to go with this structure, and handcode any
necessary processing!
NB: You'll also need to add the following
user options as shown for the specific fields. These are constants and you
can add them as they appear in the table below. BDE will add these
useroptions in when doing the conversion.
 Code example:
Code example:
CLARION:
|
Example Field Name |
Data Type |
UserOption to add |
| |
MyDateTime |
string(8) |
UnRealField |
| |
MyDateTime_Group |
group,over(MyDateTime) |
|
| |
MyDateTime_Date |
|
date |
RealField |
| |
MyDateTime_Time |
|
time |
RealField |
| |
|
end |
|
SQL:
(mssql)
Option 2: Use a DATE and a TIME datatype.
In MSSQL 2005 and up (have not tested all backends), you may match a DATE
to a DATETIME, and a TIME to a DATETIME. For DATE, it is happy to leave
the time portion = 0, but in TIME, the date portion defaults to today's
date. This will not make keys and indexes very useful! Other applications
accessing your data will also need some explanation.
Code example:
CLARION:
SQL: (mssql)
| |
MyDate |
datetime |
| |
MyTime |
datetime |
Important Note: This option should only be used for DATEs, not
TIMEs. If used for TIME (without the DATE portion) - you will be plagued
with the "Another user updated this record" error. If you have single
TIMEs then rather create the group, over and an extra DATE field. You can
then initialize the DATE portion to 0 so that all your local indexes
(using the TIME field) will be consistent. This is not an FM3 issue, but a
Clarion limitation.
Option 3: Use a LONG datatype.
Well, every Clarion programmer will jump for joy at this idea, ... BUT, is
it really a good solution? Well, you would have to analyze the situation
completely, and especially think of what may come up in the future! For
example, if you are building an app that uses it's own database, and no
other frontend apps or tools look at it, or care what's in it, then you
have no problem. But, what about those "likely-to-happen" scenarios, like
building a dynamic website from the data, or an intranet? Of course, if
you're in charge of it all you can build those with Clarion, and you have
no problems! But, if a VB guy ever came along and needed to use the data
for his application, oh boy - I guess at this point you could start a "Why
Clarion is the best RDA tool" argument! Otherwise, if you, and only you
(or any other Clarion programmer) are going to be using the data - joy joy
and more joy - keys are a breeze, date calculations are a breeze,
formatting display is a breeze, and it's only 4 bytes of data each!
<sigh>I love Clarion!</sigh>
Code example:
CLARION:
SQL: (mssql)
| |
MyDate/font> |
int |
| |
MyTime |
int |
Note: FM3 now optionally creates a utility
MSSQL Stored Procedure (
ds_ConvertClarionDateTime)) for
converting your Clarion date time integer values to a valid mssql
datatype! This will benefit other applications using your data, by
allowing them to retrieve the datetime datatype version of your data.
Click here for more info.
Option 4: Use a STRING or CSTRING datatype.
Hmm, sounds like a reasonable suggestion? Let's think about it. For
indexing purposes you are forced to use a "yyyymmdd" and "hhmmss" format
(you could of course use "-" or ":" separators). No problem, but if you
need to do calculations, you'll have to deformat all the strings first -
so, maybe not such a big deal, but remember any other programs using the
data will also have to deformat it for their use, and they don't
necessarily have the blessing of a DEFORMAT function! It also uses more
space than LONGs - 8 bytes for date and 6 bytes for time (and more if you
use the separators) instead of 4 bytes each!
Code example:
CLARION:
| |
MyDate |
string(8) |
! or cstring(9) |
| |
MyTime |
string(6) |
! or cstring(7) |
SQL: (mssql)
| |
MyDate |
char(8) |
/* or varchar(8) */ |
| |
MyTime |
char(6) |
/* or varchar(6) */ |
Memos
Did You Know?
Memos are NOT directly supported in Clarion's SQL drivers.
What to do:
Either:
Use the ForceSQLDataType = Text
field
user option
(if the backend you are using supports the text character or equivalent,
which is an equivalent for a MEMO).
Or:
Convert all your MEMOs to STRINGs or CSTRINGs.
Reals
Did You Know?
The native MSSQL driver does not directly support the REAL datatype.
What to do:
Leave it as REAL. For Oracle, change to SREAL.
If you import a float from MSSQL to the dct, it generates a Clarion REAL.
For this reason, FM3 handles the creation of a float datatype in MSSQL.
Arrays (Dims)
Did you know?
The native SQL drivers do not directly support the DIMs. Prior to
upgrading to SQL, you must first convert your DIMmed fields to an array
over a group in your last TPS version. In your SQL version, wherever you
use the array in code, you need to either declare a DIMmed variable over
the group, or re-code to use the new fields in the group. The idea is that
your DIM fields are overed over a group of values in the TPS version. FM3
handles this structure.
Code example:
CLARION:
| |
MyDim_Group |
group |
| |
|
MyDim_1 |
|
string(20) |
| |
|
MyDim_2 |
|
string(20) |
| |
|
MyDim_3 |
|
string(20) |
| |
MyDim |
string(20),dim(3),over(MyDim_Group) |
SQL:
| |
MyDim_1 |
char(20) |
|
| |
MyDim_2 |
char(20) |
|
| |
MyDim_3 |
char(20) |
|
Dynamic and Static Indexes
Did you know?
The Clarion native SQL drivers do not support Dynamic and Static Indexes.
What to do:
Change them to keys, or delete them.
If you have any dynamic or static indexes defined in your dictionary, you
will need to delete them, or change them to keys.
Oracle
DataType Matching
Did you know?
Clarion Datatypes do not match Oracle Datatypes directly.
What to do:
Follow the advice and recommendation below.
This may be obvious for most SQL datatypes, but in Oracle we have found it
to be significantly different. For example, if you import an oracle table
into your dictionary, you may get a lot of PDECIMAL fields you weren't
expecting. This is because, depending on who is master, the datatype must
be "big enough" for the other end! i.e.. The max value contained in a
Number(3) can be 999, but that's to big for a BYTE which can has a max of
255, so a SHORT is declared. But, going the other way around, the max
value of a SHORT is 32,767 which is too big for a number(3), so Number(5)
is created! With FM3, we needed a rule, so we don't go around in circles
converting datatypes endlessly! We decided that in FM3's case, the
Dictionary is the master, and therefore the backend must be "big enough"
to handle any data passed from the frontend. Here a couple of tables
showing the import and create matches:
Table import from Oracle:
| |
Number(1) |
byte |
|
| |
Number(2) |
byte |
|
| |
Number(3) |
short |
|
| |
Number(4) |
short |
|
| |
Number(5) |
long |
|
| |
Number(6) |
long |
|
| |
Number(7) |
long |
|
| |
Number(8) |
long |
|
| |
Number(9) |
long |
|
| |
Number(10) |
pdecimal(11) |
|
| |
Number(11) |
pdecimal(11) |
|
| |
Number(12) |
pdecimal(13) |
|
FM3's creation to Oracle:
| |
byte |
number(3) |
|
| |
short |
number(5) |
|
| |
long |
number(10) |
|
| |
pdecimal(x) |
number(x) |
|
| |
pdecimal(x,y) |
number(x,y) |
|
Large String Data
(greater than record or datatype limit)
Did you know?
Most SQL databases have a record size limit. In some circumstances, this
can be changed. Please see your SQL Documentation.
What to do:
Follow the advice and recommendation below.
As with Clarion, large data is not stored within the record. The drivers
do not support Memos, but FM3 will automatically create TEXT fields in
MSSQL and CLOB fields in ORACLE to handle data larger than their
respective record size limits. Please note, you will need to use STRINGs
or CSTRINGs in the Clarion definition. At the moment FM3 does not take the
whole record size into account. It will only apply TEXT and CLOB to
individual STRINGs or CSTRINGs greater than 8k and 4k respectively.
Code example:
CLARION:
| |
MyLargeString |
cstring(10000) |
|
SQL:
| |
MyLargeString |
text |
(mssql) |
| |
MyLargeString |
clob |
(oracle) |
MSSQL -
UniqueIdentifier
Did you know?
FM3 supports the MSSQL datatype - uniqueidentifier. SQL Server does not
allow this field to be renamed (after it is created) - so you need to name
this field correctly the first time that it is added to your dictionary.
What to do:
- Your field must be a cstring 37 in your dictionary.
- You need to enter the following in your user options for the ROWGUID
field:
| |
ForceSQLDataType |
uniqueidentifier ROWGUIDCOL
NOT NULL DEFAULT NewID() |
|
In theory you can allow nulls in a ROWGUID field, but invariably you
would want to make this part of a constraint (normally primary) of the
table, in which case you will not be permitted to use NULL values. If
you would like to allow NULLs in the ROWGUID, then you can enter the
following instead:
| |
ForceSQLDataType |
uniqueidentifier NULL
ROWGUIDCOL DEFAULT NewID() |
|
- You need to add the | READONLY attribute to the field's external
name in the dictionary. If you do not do this, you will get a 22005
error when inserting a record into the SQL table.
NOTE: You must use a fully
qualified external name as well as the READONLY attribute. You
cannot simply add the | READONLY attribute to the external name
field by itself. This will result in an error 47 when trying to use
the file. You will then by unable to rename the ROWGUID field, as a
ROWGUID field is not permitted to be altered.
Image and Text types vs Binary data
In TPS files, all string data is stored as binary data. Each byte can
contain any value from 0 to 255. In SQL though, all datatypes can be
categorized into either binary or text type data types. This means that
strings can be correlated to chars 95% of the time, as they will contain
valid text data (like addresses, names, descriptions, etc.). However, in
flat-files, strings can also be used to contain binary data (non-printable
characters) – which makes them non-compatible with text based data types.
Where strings are used in TPS files for storing binary data, these fields
must be converted to binary based variable type in order to allow the SQL
backend to store this data correctly.
You need to identify each variable that contains binary data and force the
data type to convert to binary. On the Field User Options for those
fields, enter:
ForceSQLDataType binary
A Caveat with this approach: Clarion does not handle binary data in
browses very well. An alternative approach to this (depending on your
backend - PostgreSQL supports this) - is to use a larger stringsize in
your dictionary, because PostgreSQL will store non-printable characters in
a text datatype using more than one byte (up to 3 bytes for some
characters). If you have a string(20) in your dictionary, then restrict
the data entry to 20, bump the size up to 60 and this will be a better
working solution in PostgreSQL.
Note: GUIDs will be handled later on – so
leave these as they are at this stage.
Computed Fields
If you require a computed field on the backend, and you would like to use
the computed field in your application, then you'll need to add that to
your dct. You'll need to use the ForceSQLdatetype field user option to set
this up so that FM3 creates the field correctly, and does not try to alter
it (once created):
ForceSQLDataType AS <expression>
Then in the External name field option:
External Name Balance Due | READONLY
Where <expression> is an expression using the names of the fields
required for the calculation. Note: The calculation field should be added
after the other fields (used in the calculation) have been added.
Field Management(essential
reading when converting from TPS to SQL)
The standard behaviour of FM3 follows the Clarion
default which implies you can have fields in your SQL tables that don't
exist in the dictionary. Therefore, by default FM3 does not remove any
fields and keys. This ensures no valuable data is lost. If you would like
FM3 to ensure the backend matches your dictionary (i.e., the Dictionary is
the Master of the fields), use the DctMasterFields user option.
This is normally not necessary (with FM3), as your file will not error 47
if there are extra fields or fields with longer dimensions (like if you
change a string(200) to a string(100)) - but some folks like to keep it
this way. The downside with this is that if other parties use the database
(or the clients build in server side triggers for reporting or whatever)
then those fields will be used, and when you no longer need those fields
and delete them from your dct, then FM3 will delete them - making other
applications not work (because the fields have disappeared).
The difference with SQL as apposed to Topspeed, is that in Topspeed your
file structure in your dct had to match the file structure in the db
otherwise Error47. Extra fields are a no-no, different length fields, etc.
But this rule falls away with SQL as you can have fields on the backend
that aren't in your dct and your program will happily open them without
knowing the difference (as to whether they are there are not). The
question you should be asking is Why do I want DctMasterFields on, rather
than why do I want it off. Obviously you need the fields in the backend
that are declared in your dictionary.
There are Dictionary, File and Field level user options available. They
are DctMasterFields for dictionary and file level, and DctMasterField at
field level. This simply means "The Dictionary is Master of the Field(s)".
| Property |
Value |
| DctMasterFields |
1 |
This setting is overridden at each level. In other words, this option set
at field level overrides the file level option, which in turn overrides
the Dictionary level option. So, if for example you set a certain file
with this option on, you can then override that setting for a specific
field by setting the field level option to 0. You must also be aware
though, that if you add Key level options, and the key is deleted in due
course, FM3 will not know what it's setting may have been, and default to
the file or dct level setting to handle the management thereof.
For more information on how to use User Options in FM3, see the
Dictionary User Option Reference.
Note: Even if you have set the
DctMasterFields, FM3 will only do structure changes on the datatables if
there is an error opening the tables. This means that if other fields are
added to the backend, these won't be deleted, unless FM3 detects an error.
If you would like to enforce a structure change, then on the FM3 connect
window (at runtime), you can check the
Force FM3 Full Data
Structure Comparison checkbox.
Key Management (essential
reading when converting from TPS to SQL)
Keys in your Clarion dictionary are not necessarily
all vital indexes on your SQL Backend. The Clarion docs state that for
SQL, it is not vital for your keys to match exactly. Often Clarion
programmers will create keys for sorting purposes etc., which are not
necessary as indexes on the SQL Backend. In fact, for optimal SQL
performance, it's better not to create all the indexes. Most SQL Tools
have a utility, or an automatic Index Optimizing Wizard. In MsSQL for
example, there is the Index Tuning Wizard. This typically studies the
statements the server receives and suggests the indexes needed to optimize
the database based on the queries.
For this reason, FM3 does not by default create all the keys as indexes on
your SQL backend. Here's what it does. It creates all Primary Keys on the
backend, as this is both advised and essential. It will also then create
Unique Indexes on the backend based on your Unique keys in the dictionary.
Just as it won't create any other keys, it will also not manage or drop
any of the other keys declared in your dictionary. You may have keys in
your dictionary that are never defined on the backend. You may also have
indexes on the backend that are never defined as keys in your dictionary.
Because File Manager 3 is an automatic database management tool however,
we have added functionality to optionally create and manage certain, or
all of the keys you define in your dictionary. We use the ever common User
Option as an interface for this. We have Dictionary, File, and Key level
user options available. They are DctMasterKeys for dictionary and file
level, and DctMasterKey at key level. This simply means "The Dictionary is
Master of the Keys".
| Property |
Value |
| DCTMasterKeys |
1 |
This setting is overridden at each level. In other words, this option set
at key level overrides the file level option, which in turn overrides the
Dictionary level option. So, if for example you set a certain file with
this option on, you can then override that setting for a specific key by
setting the key level option to 0. You must also be aware though, that if
you add Key level options, and the key is deleted in due course, FM3 will
not know what it's setting may have been, and default to the file or dct
level setting to handle the management thereof.
Currently still functional, but phasing out to obsolete is the CreateKey
User Option. This is an exact synonym for DCTMasterKeys.
For more information on how to use User Options in FM3, see the
Dictionary User Option Reference.
Note: Even if you have set the
DCTMasterKeys, FM3 will only do structure changes on the datatables if
there is an error opening the tables. This means that if other keys are
added to the backend, these won't be deleted, unless FM3 detects an error.
If you would like to enforce a structure change, then on the FM3 connect
window (at runtime), you can check the
Force FM3 Full Data
Structure Comparison checkbox.
Note: For MSSQL backends - there is an
issue with MSSQL2000, whereby it struggles to create statistics on large
table structures (of a few hundred columns/fields). In this case, FM3
could struggle to create indices on the backend, which will result in only
primary and unique keys being created (instead of all the indices, if
DCTMasterKeys is set). Here's a note from Developer.* Blogs:
The scenario is that you have a gigantic SQL Server 2000 table--gigantic
not necessarily because it has a lot of rows, but gigantic because it has
a ton of
columns. I've inherited a couple tables like this on different
projects, tables with two or three
hundred columns. (Don't look
at me, I didn't create these tables.)
It's not uncommon to need to add a new index to these kinds of ridiculous
tables to cover a query. So you go to try and add your new index and you
get an error like this:
Cannot create more than 249 nonclustered indices or column statistics on
one table.
You may be frustrated by this initially because you know for a fact that
there are not 249 indices on this table (or maybe you do...but you've got
bigger problems in that case). What's really blocking you, though, are not
too many indices, but too many auto-computed statistics, which are like
temporary indices created by SQL Server for columns that don't have
indices. What you have to do to add your new index is get rid of one of
these auto statistics. Here's how to do that:
For some reason, the "Manage Statistics" dialog box is in SQL Query
Analyzer, not Enterprise Manager. Go to the Tools menu in Query Analyzer
and choose Manage Statistics. Choose the database and the table, then
scroll down to select a "statistic" from the list for a column you don't
care about (that is, one that is seldom or never used in a WHERE clause).
Use the Delete button to delete it.
Now try adding your new index again. It should work.
Note: one step in the above instructions
that I may have skipped is to go to the Properties dialog for the database
in Enterprise Manager and turn off Auto Compute Statistics and Auto Create
Statistics. When I solved this for myself, I had turned these off, and
then I turned them back on after I deleted a statistic and added the new
index.
This is not a CapeSoft site, so the link may not be valid:
Solution for
SQL Server Cannot create more than N nonclustered indices Error
developer. Blogs
Note: PostgreSQL users, check out the
section:
PostgreSQL - Decrementing
Indices
Connect to the SQL backend
Introduction
In terms of FM3, the most vital part of your entire application is the
Connection procedure. This is where your application makes it's first
connection to the SQL backend, and allows FM3 to perform it's
initialization process, which includes collecting some vital information
for FM3's File Management responsibilities. The Connect procedure happens
really early on in your program, and it is important that no upgradable
files are opened before or during this procedure. FM3 therefore uses it's
own system file to connect to the backend at this point. You can use one
the
template utility to
import this procedure into your application.
Connection Issues
- Errorcode 90 or failure to connect:
- Make sure that the variable you entered in the SQL_Connect
window for the owner is the same that you used in the owner for
your SQL tables, and that your owner variable (in the dictionary)
is prefixed with !.
- Make sure that you have entered the necessary Connection details
in the connect window.
- Make sure that you are using the correct user name and password,
as well as the other details required.
- You may need to specify the machine and server name (depending
on the backend):
<ComputerName>\<ServerName> - don't use localhost as
this sometimes will not consolidate a connection.
- You may need to execute the following stored procedures (SQL
Express) to add the necessary roles to the server:
EXEC sp_addsrvrolemember 'demo',
'sysadmin'
as well as:
EXEC sp_addrolemember 'db_owner', 'demo'
- Error creating the FM3 system file: Make sure that
the user that you are using to connect to the database has sufficient
rights to create /open and modify tables.
- FM3 cannot detect any connection properties for this file
(or database name not found in connect string): You have
either not given FM3 the correct connection information, or your user
rights disallow access.
- Ensure you have setup your user access rights successfully.
- Ensure that your Connection Properties are setup correctly in
the FM3:ConnectToSQLBackend Extension.
- Ensure that the owner variable that the file is set to use in
the dictionary (or in your Multi-Proj Driver Substitution setup)
is exactly the same as that set in the FM3 SQL_Connect control
template.
- Connect window re-opening: This is normally caused
by setting the filename at runtime. You may find you have a variable
that is used for the filename, and the variable is set after FM3 is
initialized.
- Connect OK from remote, but not from a local machine:
You need to install the native agent for SQL 2005 on the client PC,
which can be downloaded from:
http://www.microsoft.com/downloads/details.aspx?FamilyID=d09c1d60-a13c-4479-9b91-9e8b9d835cdc&DisplayLang=en
- The standard Clarion Connect window appears after the FM3
one does at runtime. This is normally caused by the owner
in the dictionary (or a particular file in the dictionary) being
different to the owner variable set in the FM3 Connect controls
template on the SQL_Connect window. These 2 variables must be the same
in all your files maintained by FM3 (in SQL). You may also have the
command line parameter /ShowConnectErrors in the shortcut calling your
application. Remove that.
- Not Connecting to PostgreSQL? You might be using a
different ODBC driver, the newer PostgreSQL unicode driver is:
PostgreSQL ODBC Driver(UNICODE)
In the FM3 Local Embeds|Setup PostgreSQL connect string embed point,
set:
LOC:ODBCDriver = 'PostgreSQL ODBC Driver(UNICODE)'
Advanced Topics on Customisation of the Connect window
The purpose of the Connection process is to connect to a SQL Backend.
While the user has security roles and privileges assigned by a SQL
Admoninstrator, this is _not_ program level security. It should not
necessarily be used as your program user login.
Let me explain further... In FM3's case, it is vital that the SQL user
used for the program has at least dbowner rights. This allows some
administrative tasks to be performed, which, let's face it, FM3 is in the
business of doing. You don't necessarily want your program user to have
that level of control himself. Therefore, it is possibly useful to 'hide
the connection info' from the user, and rather only let him log in to the
program with his assigned username and password. This is done using
SecWin for example.
Of course, if you don't need that level of Program security, then by all
means, prompt for the Connection info. This obviously also gives the
flexibility of connecting to any valid supported database at runtime.
Ok, so how then does FM3's new Control Template allow me to accomplish all
this? Firstly, there are embed points in all the right places, so this is
a good start. It is however important to understand each step of FM3's
Connect Process, and ensure that if any customizations are done, that FM3
still connects effortlessly, and collects the necessary information needed
for File Management.
One thing which many will ask, is how can I store the info in a different
file... i.e., not an INI file! Well, that is a good question, and it is
fairly obvious that an INI file does not hold any encryption or protection
from being read. Saving Connection info in there is not always the best
choice. Although, there may be many apps that can live with that. Don't
forget, that you don't have to make it obvious to anyone else where the
info is stored. You can tell FM3 on the local extension to use woods.dat
for example! Ok, I just picked an arbitrary name out of the sky for that
one, but you get the drift. woods.dat is not obviously an ini file. Nor is
it obvious that is stores Connection info.
Anyway, the fact is, it is still plain text, and not good enough for all
scenarios, so... option two is this... write your own 'encryption /
decryption code' and call it from the embed points of the put and get ini
routines. So someone finds your ini file which says
Password=f739kss823KSJLC((&FDLA@#%K ... and that won't be much help to
them.
The next option is to write to the registry. You can code this yourself,
but adding code to the embed points of the get and put INI settings
routines in the connect procedure. Remember to either EXIT before the FM3
generated code is executed, or omit() the FM3 generated code for that
routine.
Option 4 is
not recommended, but if you
understand the limitations, and the other options, or combination of
options are not good enough for you, then you can do the following. If you
want to use an encrypted tps file to store your settings, you must
understand that this TPS file can never be upgraded by FM3. The Connect
procedure happens before the rest of FM3's initialization code, and
therefore is not yet manageable. If you change the structure, you're on
your own! In other words, if you use this approach, which is
"not
recommended", and you send us a support email complaining of an
error 47, we will send you a link to this very paragraph! And the solution
is... you'll have to convert it yourself. Now hopefully, this will be a
very rare occurrence, because a file holding this kind of info, should not
hold much more than that, and should rarely need to be upgraded.
So, now that everyone understands, here is how you do it. In the get and
put ini routines, use omit() around the FM3 generated code, and then add
your own file handling. Alternatively, add your code in the first embed
point of the routine, and remember to exit afterwards.
Please understand that it is not always necessary to make things more
complicated than they are, and that this control template, and amount of
generated code means your program works as is! ie, setup and support
should drop to a minimum! If you make changes, be sure you understand what
is going on, and don't try to omit or workaround any of FM3's code, unless
absolutely necessary.
The next issue which is also fairly common, is when using TPS and SQL
files in your program, is it absolutely necessary to call the Connect
Procedure? Quite simply, the answer is yes. This does not mean you have to
prompt for user input... the is an Auto Logon switch, and you can
programmatically set the necessary connection variables. If you don't run
the Connect proc, then your program could continue to manage TPS files,
but would bomb out when the SQL files are accessed. FM3 initialization
code must happen at program startup. If you are brave, and wish to block
any SQL files being opened if Connection did not take place, then that's
up to you to program.
This new template is fully Multi-Proj compatible, and works very nicely
with Multi-Proj's Driver Substitution. I will be adding a Multi-Proj / FM3
example in the next little while for those who would like to see how
powerful the combination is!
Converting to SQL
Introduction
If you are not familiar with FM2 or FM3, please tryout the
example apps before attempting a SQL
conversion. Familiarise yourself with FM2's AutoUP feature by trying out
the
Jump Start example for TPS. Once
familiar with AutoUP, follow these simple instructions for converting to
SQL.
Before you start
Basic Rule
Always apply FM2/3 to your flat-file application, before attempting a
conversion to SQL.
If you have not had FM2/3 previously installed and applied to your
program, then follow the steps below.
- Before changing your dictionary, follow the steps laid out in the
Adding FM3 to your Application section.
- Compile and run your TPS driven FM3 enabled program.
- Now the UPG.tps file exists, containing valid file structures for
each file.
- Send out this update to all your clients to allow each client to
build a upg.tps file.
If you have already been using FM2/3 in your application, or have
completed the steps above, then a upg.tps file should already exist, and
you can follow these instructions.
- Make your dictionary SQL compliant (see the Clarion
/ SQL Fundamentals and SQL Data Types
sections of this document). Compile and run your application (you will
need to ship this exe to your clients, so that the TPS data is at the
latest version before upgrading to SQL).
Either:
- Generally the best approach is to use Multi-Proj's driver
substitution feature to use the same application and dictionary - with
multiple exe outputs to support different database types. In this way
you can keep supporting your TPS application without leaving your TPS
clients in the cold.
Or:
- Alternatively, in the Dictionary editor, change the driver to the
relevant SQL driver.
- Set the Owner attribute with either your connection string, or a
string variable. Read about SQL Owner Strings.
- Set the Full Path Name for SQL (e.g.: owner.myfilename). Read about
SQL TableNames.
- On the Options tab, add the string user option OldName.
- Increase the Version Number (if
using BDE - this will be done automatically)
Continued for both options:
- If your TPS file was encrypted with an owner string, then you need
to use the OldOwner user option to migrate the
data to the SQL backend
- If you have had FM2 applied, follow these steps to Convert
to FM3.
- On the Global Extension, select the
SQL driver, and leave the the previously used driver(s) also checked.
- Run the 'Import the SQL Connect procedure' template utility. You'll
need to set the Global Owner variable in the SQL_Connect window's
"Connect To SQL Backend" Control Template prompts. To do this, double
click on the SQL_Connect window and click on the "Connect To SQL
Backend" control template to bring up the prompts and enter the Global
Owner variable in the field provided on the General tab.
- In your FM3 global extension template, on the Auto Up tab, set the
"SQL Connect procedure" to 'SQL_Connect' (i.e. the new procedure that
the template utility just created).
- Compile and run your application.
Miscellaneous Topics
SQL Owners
| Driver |
SQL Owner string |
Example |
| MSSQL |
Server, DatabaseName, UserName, Password |
CRUNCHIE, CapeSoftDB, Scott, Tiger |
| SQL Express |
Machine\Server, DatabaseName, UserName, Password |
CRUNCHIE\CRUNCHIE, CapeSoftDB, Scott, Tiger |
| Oracle |
UserName/Password@Protocol:DatabaseName |
Scott/Tiger@2:CapeSoftDB |
|
UserName@Protocol:DatabaseName,Password |
Scott@2:CapeSoftDB,Tiger |
| MySQL |
DSN, UserName, Password (See
DSN-less Connections below) |
MyDSN,Scott,Tiger |
| Firebird |
DSN, USERNAME, Password (See
DSN-less Connections below) |
MyDSN,SCOTT,Tiger (note UPPERCASE) |
| Sybase/ ASA |
DatabaseName,UserName,Password;ENG=Server;tcpip={host=111.222.333.444:5555}
|
CapeSoftDB,Scott,Tiger;ENG=CapeSoftDB;TCPIP={host=127.0.0.1:49152} |
| PostgreSQL |
DSN, UserName, Password (See
DSN-less Connections below) |
MyDSN,Scott,Tiger |
SQL TableNames
| Driver |
Table name |
Example |
| MsSQL |
TableOwner.TableName |
dbo.Customers |
| Oracle |
UserName.TableName |
Scott.Customers |
| Oracle XPress (10g) |
TableName |
Customers |
| MySQL |
DatabaseName.TableName |
CapeSoftDB.Customers |
| Firebird |
TABLENAME (Case-sensitive - UPPERCASE recommended) |
CUSTOMERS |
| Sybase / ASA |
UserName.TableName |
Scott.Customers |
| PostgreSQL |
SchemaName.TableName |
public.customers |
Check out the
HotTips section for more Database
specific topics.
ODBC
How to set up an ODBC Data Source Name
(DSN)
This section will show you how to set up a Data Source Name for your ODBC
connections. It also gives examples of a DSN-less connection.
The exact steps may vary slightly between operating systems.
- Start > Settings > Control Panel.
- Administrative Tools. (2K, XP, 2003, Vista)
- Double click on ODBC Data Sources.
- Select the System tab.
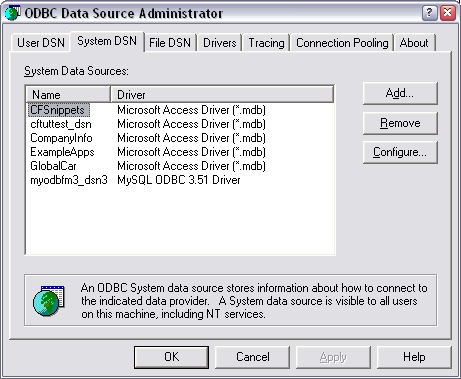
- Click on Add.
- Select the driver you wish to use, and click Finish.
- Type in a descriptive name e.g.: 'MyApp_dsn' , and follow the
prompts for setting up your driver's DSN.
This name can now be used as your connection string.
How to set up an DSN-less Connections
(DriverConnect)
A DSN-less connection does not require the above steps, but rather a
connection string, semi-colon separated with the driver and connection
details:
Here are 2 examples:
DRIVER=MySQL ODBC 3.51
Driver;SERVER=MyServer;USER=MyUserName;PASSWORD=MyPassword;DATABASE=MyDB;
DRIVER=SQL
Server;SERVER=SQLBox;UID=Bill;PWD=micro$oft;DATABASE=Northwind;WSID=BillsWorkStation;APP=Microsoft
Open Database Connectivity;
Oracle TableSpaces
File Manager 3 now supports the creation of tables
into a designated Oracle TableSpace. It is advised that you create this
TableSpace manually before allowing FM3 to create the tables. This ensures
your full control of the TableSpace definition. That said though, FM3 will
create the TableSpace for you if it does not exist. To use this feature,
we've added String User Option which can be set at File or Dictionary
level. This user option takes the form of a comma separated string as
TableSpaceName, TableSpaceDataFile, TableSpaceSize. The TableSpaceDataFile
and TableSpaceSize parameters are optional, but FM3 defaults these to the
default Oracle Data Folder, and 50M size.
| TableSpace |
MyTableSpace,C:\Oracle\OraData\MyTableSpace\MyTableSpace.ora,100M |
Here is an example of the code generated by FM3 to create the TableSpace:
Create TableSpace "MyTableSpace"
Logging
Datafile 'MyTableSpace.dbf'
Size 50M
Extent Management Local |
Please note that the File definition overrides the Dictionary setting.
i.e. If you have a dictionary level TableSpace option set, and you have a
file level TableSpace option, the file level user option will be used for
that file.
Please note too, that the directory for the datafile setting must exist!
We have also added the ability to create your indexes and keys in a
separate TableSpace. This is done in much the same way as the TableSpace
option, although this can be set at Key, File and Dictionary level. Again,
the Key user option has higher priority than the file, which has higher
priority over the dictionary level user option.
| IndexSpace |
MyTableSpace,C:\Oracle\OraData\MyIndexSpace\MyIndexSpace.ora,100M |
Accessing Multiple
Databases in one program at the same time
File Manager 3 can only manage one database at a time. (Managing in this
context refers to upgrading files etc.)
In other words, if your program connects to database A, then FM3 will only
upgrade the tables on that database.
While FM3 is connected to database A, your program will still be able to
access other databases in the normal way.
The Owner of the FM3 table (e.g.: gMsSqlFile) dictates which database will
be managed. Thus in order to manage a second database, you must restart
the program, setting the owner appropriately.
If you would like to connect to another SQL database simultaneously, then
you will need to suppress the FM3 conversion for those specific tables
(this excludes flat files like topspeed and dat files, etc.). Click
here to find out more information on how
to do this.
Hot Tips
General SQL
MSSQL
Firebird
PostgreSQL
General SQL
SQL Backend
Case-Sensitivity
FM3 Supports both Case-Sensitive, and Case-Insensitive SQL Backends. But,
for Clarion 5, FM3 assumes the backend is case-insensitive (MSSQL Default
Install). Clarion 5 only supports a Case-Insensitive backend.
Converting TPS Zero and Blank data to NULL in your SQL database
TPS does not store true NULL values. Numeric data is stored as zero, and
empty character data is blank (spaces). In order to use the functionality
of NULL in a SQL backend, we have implemented a template option to set
your Zero or Blank data to NULL in the backend during conversion. You will
find this on the new SQL Advanced tab on the Global Extension, default
off. When off, FM3 converts Zero data to zero data and blank data to blank
data (spaces) in your sql backend (not null).
You can now use this option at all levels - Template / Dictionary level,
File level, Field level. Just the ZeroNull to the User Options tab in the
dictionary:
ZeroNull 1
ZeroNull can be set to 1 (true) or 0 (false). Please note that a Field
User Option overrides a File User Option for that field, and File level
ZeroNull overrides a Template / Dictionary level option for that
particular file.
Are you not sure whether you need to use NULLs or not? Check out this
article:
http://www.sqlservercentral.com/columnists/mcoles/fourrulesfornulls.asp
Server side
Auto-incrementing
In flat files, your application has to handle auto-numbering for your
auto-incrementing keys. You can still use this in SQL, but there are some
disadvantages to this approach - especially if multiple applications are
writing to the database simultaneously.
In order to effectively implement Server-side auto-incrementing, you need
to do the following to your table in your dictionary:
- If you are converting from TPS to SQL, then you need to remove the
Auto Number attribute from the key. Server-side
auto-incrementing is field based, not key based.
- On the field that you will be auto-numbered, go to
the Options tab, and enter 2 User Options there: AutoNumber = 1, and
IsIdentity = 1.

- On the file properties, if you are wanting to
mimic client-side autonumbering (for child records) - then you need to
add the EmulateAutoNumKey = 1 to the File User options. Take note:
this is not optimal for strict sequential numbering (like for
invoices) - as cancelling an insert can create sequential gaps.
- On the file properties, in the Drive options field
(on the General tab), you need to enter the /AUTOINC select statement
that will be used to select the next value. The value will determine
| SQL Backend |
Driverstring to add |
| PostgreSQL |
/AUTOINC='SELECT
currval(''schemaname.tablename_fieldname_seq'')' |
| MySQL |
/AUTOINC='SELECT LAST_INSERT_ID()' |
| MSSQL |
/AUTOINC=SELECT SCOPE_IDENTITY() |
| MSSQL (old) |
/AUTOINC=SCOPE_IDENTITY() |
NOTE: At the time of writing this, this is a Connection level driver
option, so it's important you add it to the FM3 connect file driver
options (in the global extension template). If you're using MultiProj's
Driver Substitution and you're substituting to SQL, then enter the driver
string in the "Send" field of the "Override Driver Possibilities" option.
A note for PostgreSQL users:
PostgreSQL handles auto-incrementing differently from other databases. A
sequence is not automatically invoked. It is a default constraint which is
used only if no value is passed. Clarion (bydefault) passes a value -
other SQL backends ignore this value when inserting a record, whereas
PostgreSQL will apply this passed value - thus not auto-incrementing the
field.
There are 2 ways to handle this:
- Call the nextval(Sequence) function before you insert the record,
and assign that value to the field. The advantage of this is that you
already know what the value is, so in the case of child tables you are
set for good.
- Make that field readonly in the dictionary, such that the query
generator will not pass a value in the insert/update queries.
MSSQL
Utility Stored Procedures
The first in this section is a MSSQL Stored Procedure for returning
Clarion date and time integer values in MSSQL's datetime datatype. For
example, it is in many ways nicer to store dates and times as a Clarion
long (eg: 73838 = Feb 25, 2003 and 5400001 = 15:00), as it makes keys and
mathematical calculations much easier. But, this data would be useless to
any non-Clarion program, unless converted to meaningful data. This is what
ds_ConvertClarionDateTime does. It takes 2 input parameters, 1 output
parameter, and a return status. You can optionally convert on a date value
or time value, but must pass a value of 0 (zero) into the "unwanted"
parameter.
Example: (Calling from SQL Query Analyser)
| Example |
declare @rs int -- return
status
declare @cd int --
clarion date
declare @ct int --
clarion time
declare @sdt datetime --
sql datetime
set @cd = 73842 --
March 1, 2003 - 0 if "blank"
set @ct = 5400001 -- 15:00 - 0 if "blank"
exec @rs
= ds_ConvertClarionDateTime
@cd,@ct,@sdt output
if @rs = -1
-- Both date and time parameters are zero
print 'Zero Date and Time!'
if @rs = 1 --
Integer value is greater than valid clarion date
print 'Invalid Clarion Date!'
if @rs = 2 -- Integer value is greater than
valid clarion time
print 'Invalid Clarion Time!'
select @sdt as 'Returned DateTime' |
MSSQL: Importing and Exporting MDF and LDF
files
Importing a MSSQL database from an LDF and MDF file:
- Open the SQL Management Studio.
- Right-click 'Databases' and select 'Attach' from the drop down menu.
- Click Add and locate the MDF file that contains the database
structures.
- Click OK - if there is an error locating the corresponding LDF file,
then use the ellipses button corresponding to the LDF file to locate
the correct LDF file.
Exporting an MSSQL database to an LDF and MDF file:
If you're struggling with an aspect of FM3 - where FM3 is not maintaining
your database correctly, then we could request a database dump - which
consists of an MDF file and an LDF file, together with your dictionary and
the UPG.tps file that corresponds with that dump. This is how it's done:
- Open the SQL Management Studio.
- Right-click on the Database that requires exporting and select
Properties.
- On the Files Properties window make a note of the mdf and ldf files
used for the database.
- Return to the main window - Right-click the database and select
detach from the Tasks menu.
- The files that you need to send are the mdf and ldf files indicated
in step 3.
MSSQL: Restoring a backup database to a new one (on a different server)
This is very simple, but if you don't know the couple of steps, it can be
very frustrating.
- Copy the backup file (<databasename>.bak) to a place on the
server pc (preferably).
- in Management Studio: Create a blank database on the server.
- Right click on Databases, and select Restore database.
- Select the new database you just created from the To database drop
list, and then enter the filename you copied in the From device field
(not that simple - but following the steps is pretty straight
forward).
- Check the Restore checkbox next to the filename in the list when it
appears.
- Click on the options (in the Select a page list) - and check the
Overwrite the existing database checkbox (this is the magic you're
after - omitting this step will lead to lots of frustration).
- Now click the OK button - and make some coffee/tea/etc. while it
performs the restoration.
Connecting to your MSSQL Server using a non-Standard port
You cannot do this directly using the Clarion MSSQL Driver, but you can do
this by creating an alias in the MSSQL Client manager. If you want to
create a registry entry in your app you can do with:
PUTREG(REG_LOCAL_MACHINE,'SOFTWARE\Microsoft\MSSQLServer\Client\ConnectTo','MyServer','DBMSSOCN,211.68.105.49,2433')
and then you can use the next owner attribute,
'MyServer,<database>,<uid>,<pwd><;LANGUAGE=language><;APP=name><;WSID=name>'
What FM3 does not
support in MSSQL
- Schemas. At this stage you have to use the default schema 'dbo'.
How to prevent
duplicate records appearing in a browse
- Add a Manual Sort order with main the Sort Column/Field and also the
Record Primary Key as a Secondary then the Duplicates disappear and
Column Header Sorting works.
Also ensure that your primary key fields are added as hotfields (and
into the view) if they are not already in the browse.
Firebird
Firebird Tips
These notes were created using Firebird v1.5.2 CR1 (which is Firebird
version 1.5.2.4634).
Downloading Firebird
There are two websites for the Firebird downloads, but the first is more
useful:
You’ll need to download and install three items:
- The Firebird install for Windows
For example: Firebird-1.5.2.4634-1_RC1-Win32.exe
Tip: Turn on the Copy Firebird
client library to <system> folder option during
installation.
- The Firebird ODBC drivers:
For example: Firebird_ODBC_1.2.0.69-Win32.exe
You will need these ODBC drivers installed on each machine that will
be running your application so that it can connect to your database.
An admin tool for managing your databases.
I recommend HK-Software’s IB Expert (www.h-k.de)
A free personal edition is available and does the job very well.
For example: ibep_2004.10.30.1_full.exe
Tip: The first time you run this app it
displays an error. Just try again.
SYSDBA User & Password
The default username and password is:
Username:
SYSDBA
Password:
masterkey
Creating Your Firebird
Database
FM3 requires that you have already created a (blank) database in your SQL
backend. (FM3 will create all the tables and keys* for you, you just need
to create the database).
* Not all keys are created by FM3, just the ones it needs, but you can
override this.
Make sure Firebird is running (you can start it from your Control Panel).
Using IB Expert create a database such as the one below (Database | Create
Database):
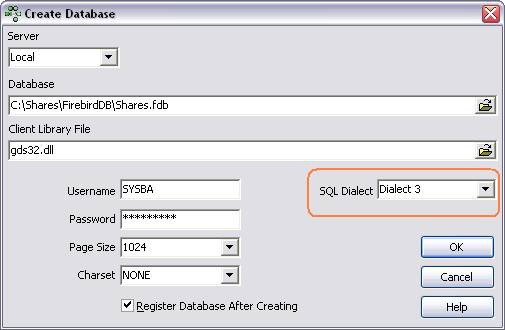 Note
Note: You must use
Dialect 3.
Note: If you are running firebird as a
service, then the file path must be accessible to the service.
After creating the database (or if you have already created it), you can
view the database, with the following registration information:
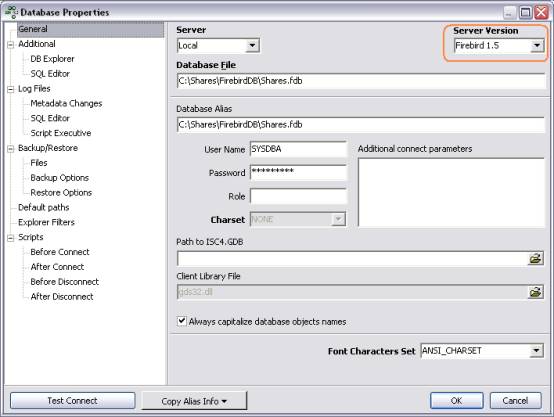
You’ll then see your Database listed in the IB Expert database list. If
you double click on it, you’ll see the database properties:
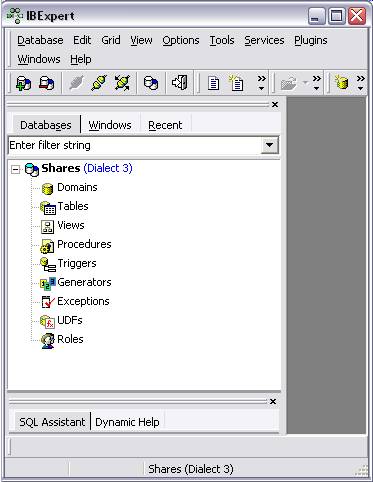
GDS32.dll
Without this DLL your Firebird applications won’t work. After installation
you should find it in your Windows\System32 folder. It’s probably worth
shipping a copy of this DLL with your application.
Key Limitations in Size
Firebird Indices (keys) have a limit of 254 characters, depending on the
character set, so it may be less. You may have to shorten some of your
keys or fields in order for Firebird tables to be made.
Key Sort Orders
Each Firebird Index can only contain either all ascending or all
descending Key Sort Orders.
NOTE: At present, FM3 will only create and maintain ascending keys in
Firebird.
Key Limitations in
Duplication
Firebird doesn’t like have two unique Indices with the same fields in
them. For example the following are not allowed:
DateKey: Date, Share
ShareKey: Share, Date
You’ll need to either add or remove fields from the keys or make one of
the keys non-unique.
Connecting to a remote Firebird Database (in an FM3 enabled
application):
In the Connect window:
- Make sure that you've entered the username in uppercase,
- The password is case-sensitive and must match that of the created
database.
- ODBC Backend must be FireBird (In the configure section)
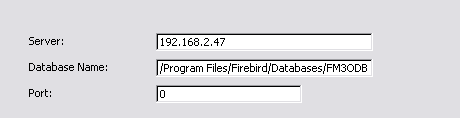
- The key is getting the Server and Database Name correct. The
Database Name is the relative name of the .GDB file that
contains the database. The Server name is either the
resolved machine name or IP Address. The Port is not
used. Here's an example:
PostgreSQL
PostgreSQL - Binary Strings
The char and varchar character types in Postgres are quite rigorous in the
use of non-characters used. In Clarion, a string is basically a binary
collection of ASCII bytes - which can normally be equated to a char type
in Postgres because of the nature of data stored in strings (addresses,
names, comments, etc.). However, because of the potential that Clarion
possesses in the Topspeed driver to store non-printable characters (or
binary characters) in strings, this can mean that equating a string to a
char in Postgres can have adverse effects - i.e. your TPS data string will
not be converted into the Postgres database. This is particularly
prevalent in GUIDs (used with Capesoft's Replicate) which will mostly
contain binary data.
There're a few ways of working around this issue:
- Use the ds_SetMakeGUIDsBinary(1) function before the FM3 init code
runs. This will basically ensure that all GUIDs in all your tables
will be created as type bytea (or the equivalent of a binary string in
Clarion) - without making any changes to your dictionary. This will
cater for the use of GUIDs in your dictionary. You only need this for
existing applications that used Replicate v2.10 or less at any stage.
Applications that only started using Replicate at Replicate version
2.11 or above, are generated with GUIDs that are legal text
characters.
- Use the | BINARY dictionary switch in the external name (see the
dictionary help on External name options) to inform FM3 that this is a
binary string and should be created as 'bytea' on the backend, as
apposed to the default char type. This will cater for non-GUID fields
that contain binary data.
The following characters are unusable in text based datatypes (like chars,
varchars, etc.) in PostgreSQL:
- chr(0) - this is stored as chr(32)
- chr(10) - this is stored as chr(13)
- Range: chr(128) to chr(255) - these cannot be stored legally (in one
byte) - some of these chars are stored in 2 or 3 bytes.
PostgreSQL - Clarion
Version support
Why does FM3 only support Clarion6 and up? FM3 uses a generated
maintenance file to connect to the database and query system tables. There
is one for each driver supported (MSS, TPS, ODBC, etc.) - the ODBC file is
called gODBCFile. The ODBC generated file contains uppercase field names,
which are necessary for FireBird support. In Clarion6, the external name
is treated as case insensitive - thus ds_field1 is equated to DS_FIELD1,
but in Clarion5.5 and below this is not the case. Field names are created
as lower case, but when queried, the case is expected as upper, and so the
field names don't match (hence error 47). This makes multiple ODBC backend
support impossible in previous versions of Clarion.
PostgreSQL -
Decrementing Indices
PostgreSQL does not support decrementing Indices. For more discussion on
this topic, please see:
http://archives.postgresql.org/pgsql-general/2002-03/msg00092.php
Peculiarities in PostgreSQL
Turning off the CR/LF conversion (to LF only).
By default, PostgreSQL converts the CR/LF to LF character when inserting
and upgrading records. This means that insertions into the database get
added with just an LF. However, this can be problematic for fields with
existing data (with CR/LF charset) - because the data is read and arrives
at your clarion application with the CR/LF charset, but when it is added
back, the record is encoded to just the LF and compared to a reget (which
has the CR/LF character). This will then be marked as different from the
original, and so a "This record was changed by another station. Those
changes will now be displayed. Use the Ditto Button or Ctrl+H to recall
your changes" error.
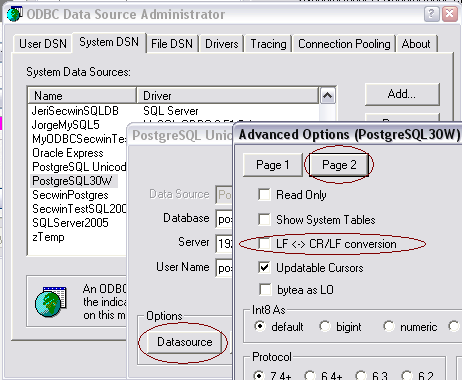
In order to bypass this error, you need to turn the CR/LF conversion off
in the odbc driver.
If you are connecting via a normal connection (i.e. non-DSN) then you need
to add the LFConversion=0 to the driver string (which you can insert on
the AutoUp tab).
If you have a dsn connection, then you do this as follows:
PostgreSQL
- Getting things going, Drivers and resources
What you'll need:
Some steps to get you going:
- Install the server on the database machine (and run it, pretty
straight forward)
- Setup the accountname details on the server machine database.
- On the client machine, install the GUI interface to the server.
- The crucial thing is to grant access on the Server side (for the
client). You do this in the pg_hba.conf file
(which is in the C:\Program Files\PostgreSQL\8.1\data directory by
default, or wherever you installed the Server).
You need to put the following line in:
host all all 192.168.2.3/32 trust
for access for your local machine.
It seems like 0 works as a wildcard, so 192.168.2.0/0 would allow the
same machine and others to connect.
If you get a Can't Obtain databases error when running the Client
application, then you've set this up incorrectly. The first time I did
it, I didn't put the /32 in. It's really fussy about that.
- The next crucial thing to do on the server side (for the client) in
granting access to the client, is to modify the postgresql.conf file
to tell PostgreSQL which addresses to allow access to the server.
Open the postgresql.conf file (which is in the C:\Program
Files\PostgreSQL\8.1\data directory by default, or wherever you
installed the Server) with a text editor.
You need to put the following line in:
listen_addresses = '*'
- Install the ODBC driver on the Client machine. For FM3 (at the
writing of this) you'll need the PostgreSQL Unicode
ODBC driver (32 bit one whether on 32 bit or 64 bit OS systems). Make
sure that this one is installed when you install the ODBC driver. If
you already have a PostgreSQL driver installed (but not the PostgreSQL
Unicode driver) - then you'll need to run the upgrade.bat file that is
included in the ODBC install zip. Otherwise, you can simply run the
msi install file.
- It's a good idea to setup a DSN on the client machine to test the
connection (the first time you work with PostgreSQL):
http://www.sevainc.com/access/PostgreSQL_ODBC_Configuration.html
(not a CapeSoft link, so may not be valid in future). NOTE: If you are
using a 64 bit OS, then you must run the
C:\Windows\SysWOW64\odbcad32.exe to register a DSN (not the
odbcad32.exe, which by default will point to the 64 bit DSN manager -
I know, it's the wrong name - don't ask, I don't make the rules).
Note: You may have some issues when
connecting to a different machine (i.e. where the Server resides on a
different machine to the client application). Anti-virus could be the
culprit or your Firewall. The best solution would be to first try and
allow the PostgreSQL port - by default 5432 - failing that, to disable the
Firewall and/or Anti-Virus temporarily during your test.
Clarion / SQL Related Links and Resources
- If you haven't already, read this document! To
Top.
- Dan Pressnell of Toolwares
has written some excellent Articles entitled "The Better SQL Series". These can be found on
the IceTips
site.
- ClarionMag
is an excellent resource containing many articles by many Clarion
programmers. Note: This is a paid for subscription based resource.
- ClarionLive
is also an excellent resource for Clarion Programmers.
- And, one of the best places to find information are the SoftVelocity
newsgroups.
