REPLICATE FOR DUMMIES
By James Fortune
Note: This is purely the opinion of the author. While
CapeSoft, it's employees and owners (hereafter referred to as 'we') have done our best to proof read this
document, we cannot be held responsible or liable for any damages, misunderstandings
or losses whether implied or specific, direct or indirect because of the use of
this document. By reading this document it is implied that you agree to these
conditions.
Do your users drive you mad asking 'Can I copy my data onto my laptop'? Are you
asked by your bigger clients to design systems so that their branch offices can
update the Head Office with their 'figures' each evening? And what about roving
sales people: all with different sets of data on their laptops? These are nightmare
scenarios, aren't they?
Well, not any more! Replicate is here to do all this for you and more with just
a few clicks of your mouse!
So What is Replicate?
It is a set of CLASSes and templates that enable you to offer full Replication
& Synchronisation (R&S) to your Clarion applications. R&S enables
the sharing of data from one database (or more accurately: one site) to another.
This was previously only available if you used SQL as your backend. Now it's available
for any file driver: including TPS files!
Basically it works by logging all adds, changes and deletes done on a particular
computer (say, a sales person's laptop) and then uses a 'transport' of your choice
(a local area network (LAN), FTP or even email), to export the modifications to
another site (say, the Head Office server), where these modifications are absorbed
into that data 'set'. No more heartaches with attempting live links, hand-coded
imports, user dependency, etc. This all happens on the fly and behind the scenes.
It is foolproof! It doesn't even matter what file driver you use: you can even
mix them up if you want!
How Does Replicate Work?
In a nutshell, you add an extra field and a key to each data file in your dictionary
whose data you want to be able to synchronize. The field, called the Global Unique
Identifier (named 'GUID'), is used to uniquely identify every change a user makes
to his or her data 'set' when it is written to a log file.
There is even a little program (the Bulk Dictionary Editor) supplied that will
add this field, its key and (optionally) a SiteID field to all the relevant files
in your dictionary - automatically!
You will also need to create a Log Manager program. The easiest way to do this
is to take one of the example APPs and recompile it with your dictionary, once
you've added the necessary fields, etc.
How Do I Get It Working In My Application?
- Decide how many 'sites' you have.
A 'site' is simply a set of data that one or more of your applications
may use.
For example:
- There is a database at the Head Office. It's a sales database, with stock, orders,
invoices and so on. There are four in-house sales people who sell over the
phone and all four of them have access to the same database on the server.
This is your first set of data or site.
- You also have a roving salesman with a complete database on his laptop. This
is another set of data or site.
- Finally, you have a branch office with another two operators who use a database on
their server. This is the third set of data or site.
So, in this example, we have three sites. (Although
there may be seven operators running the program, there are only three sets
of data - thus three sites.)
- Label your sites appropriately.
For this, you use the Site Identifier which is a STRING(4).
The 'top' site, the site with no parent site, is called the Primary Site
and you can only have one Primary Site for a particular application. The database
at the Head Office will be the Primary Site and this should have a Site Identifier
of B000. Why don't you label the Primary Site as A000? Because your client might
expand in the future and you might need to add a new Primary Site that owns
your existing one.
All sites below the Primary Site should be numbered so that it is easy
to see who they belong to (e.g. B100, B200, B300 and so on). Think of the days
when you had to number your BASIC programs. You always used line numbers in
jumps of ten or a hundred, didn't you? This allowed the insertion of additional
lines if necessary. Well, number your sites in that way too. It's good practice
and could save tears later. Sub-sites or 'Children' of a site would continue
this numbering, such as B110, B120 and so on. Stay with me, this will all become
crystal clear in one moment.
- Draw a Site Diagram Replicate requires a one-to-many parent-child site structure, each child
site can only have one parent site (although a parent can, itself, be a child).
This is the Site Diagram of the example above.
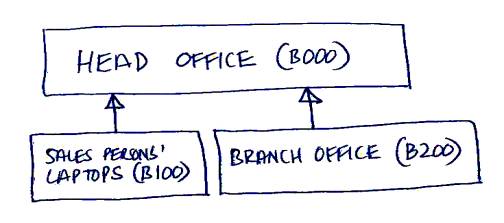
Each box represents a site and the arrows represent the parent-child relationships,
not the direction of replication. Replication is completely bi-directional.
But a particular site can only synchronize with its 'parent' site. So both B100
and B200 can synchronize with B000 but not directly with each other in the field.
Here is the Site Diagram of a more complicated structure:
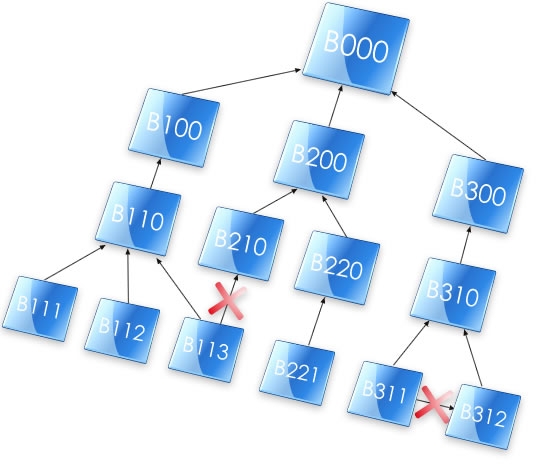
B000 is the Head Office and B100, B200 and B300 are regional offices. B110,
B210, B220 and B310 are branches/stores/shops that report to those regional
offices. The bottom layer are roving sales people with laptops. Branch B110
has three roving salesmen - B111, B112 and B113. Branch B220 has just one, B221,
while branch B310 has two - B311 and B312.
The red crosses indicate illegal relationships. It is illegal for a site
to have more than one parent. In reality, this means that salesmen B311 and
B312, for example, cannot synchronize their data with each other while in the
field, they have to do it through their branch B310.
Replicate can use the Site Identifier to distinguish between different
sub-sets of data that are only relevant to certain 'branches' of the structure.
For example, you might only want to distribute file changes that pertain to
the B100 family (which in this case would include B110, B111, B112, B113) instead
of the entire log file.
- Follow the instructions
in the main Replicate Help file to modify your dictionary to enable Replicate
to work in your application or, even better, use the supplied Bulk
Dictionary Editor utility to do it for you.
Incidentally, if you are sending out the
'Replicate-enabled' version of
your application to existing users, there is a code template called SetSiteIfNew
which will enable you to set all new occurrences of the Site field to whatever.
Obviously, you will need to call a procedure, after FM3 has done its
stuff, that runs this the first time a site is 'Replicate-enabled'.
Tip : Don't consider going down this road at all unless you have FM3/FM.
Basically ALL your structures are going to need converting, probably
more than once. If you have to keep the files updated the hard way
then it's going to be very painful - and it might even get to be impossible
if you're dealing with already existing sites!
- Create your Log Manager program.
- Implement the 'communication' path between your sites. Replicate has this already built
in when on a LAN. If you want something more flexible, such as email, we recommend
you use NetTalk.
- That's it!
I Need To Understand This a Bit More
The most important feature that makes Replicate different from other Replicate
& Synchronisation systems is that it is totally AUTOMATIC and, therefore, 'invisible' to the end user.
Let's talk about the simplest example: an office computer and a laptop. Some
of the time the laptop is in the office, connected to the office computer via
a LAN, and sometimes it's out on the road. The laptop will ALWAYS use its own
copy of the database. It will never see the office computer's data directly.
When it's in the office, and connected to the network, any changes made by its
user are made first to its local copy of the data, and then immediately
sent to the office computer or server for merging into the main database. And
vice-versa. Any changes made to the main database are immediately replicated
in its database. We say immediately but you can configure what the synching interval
is: daily, hourly, every couple of seconds: whatever suits the situation. The
users won't even be aware of it because this process of synchronisation is entirely
'behind the scenes'. No-one actually chooses an option in the program called 'Synchronise'.
Replicate ensures that the office computer and the laptop keep each other's data
sets up to date, automatically.
Now, if the laptop user leaves the office (to go home or on a trip), the laptop
is 'undocked' from the LAN physically. The transport detects that the connection
has been broken and the Log Manager programs at both ends start 'logging' all
database changes to a log file. Anytime he reconnects, either by redocking the
laptop to the LAN or even dialing into the office through a modem, both sides
are immediately updated with these changes.
The implementation of this is very easy. Firstly, you consider these as two separate
'sites' and you install your program onto both computers. During installation
you set up some replication options such as pointing one system to the other.
You will also set up some communication between the two: let's say for now, a
LAN.
So How and When Does Synchronising Happen?
As soon as the two 'ends' can 'see' each other. As soon as a laptop is connected
to the LAN, for example. If a log file exists on your machine, your Log Manager
sends it off to your 'parent' database's Log Manager via the communication transport
you select and receives any outstanding log file from the 'parent' database's
Log Manager. The communication transport is then closed and the respective Log
Managers then merge the data in the received log files with their data 'set'. It's as simple as that!
How Are Conflicts Handled?
Firstly, we need to determine what a 'conflict' is.
R&S doesn't add any more conflict issues than you already have when you run
your program on a LAN. If User A & User B are simultaneously changing the
same field, Clarion's Concurrency checking kicks in but if User A sets a date,
say, to 12/12/02 and fifteen minutes later User B changes it to 12/12/03, does
your program kick up a fuss? Of course not. So why should an R&S system? Acclaim
Software (James Fortune)'s program Professional Investigator has always had an
additional six 'audit' fields for every file/record: Date Created, Time Created,
User Created, Date Last Amended, Time Last Amended, User Last Amended. These ensure
that User A knows that User B last amended the record and when, so if there is
a dispute, he knows who to ask. This would adequately cover any automatic changes
done during a synchronisation, wouldn't it?
All you have to remember with R&S is that there is no record locking. So you
will almost certainly want to limit access to most users depending on their "responsibilities"
and so on. It is OK for "everyone to change anything" - but if
User A makes a change to a record, and User B also makes a change to the record,
then one of the changes will be lost. Any security template which
supports limiting access based on the record being changed (such as SecWin) should
do the trick.
Some R&S systems simply say that during synchronisation someone has to be
in charge to determine which value is the right one if a field in a record has
a different value at 'both ends'. They describe it like this 'MyGreatProgram makes
it easy to resolve conflicts by presenting you with a wizard that shows you the
exact detail on each conflict between the master file and the replica.' Notice
the word 'you' is used twice: who is 'you'? In the real world, this 'you' could
be many different people and, indeed, in many cases this 'you' simply doesn't
exist. The problem is that this person will be different depending on the data
being changed. Who will be the 'you': the 'syncher'? The person in charge of
one part of the data? Even if you make one person in the organisation responsible
for all the synching then most of the information would be nonsense to
them. And what if he or she is not available? No matter who the syncher is, 99%
of the stuff it will ask him to decide about he will have to go to someone else.
Now let's say you're the person who gets a few of these every day. You don't know
who was right (Bob? Pete? Mike?) so you have to phone at least two of them. Assuming
they're in. the whole process takes you maybe five minutes. So you can do roughly
ten of these an hour. This is completely unscalable - it's a pain with 10 users,
a major problem with a 100 users and completely unworkable at 1000! How long before
'you' start ignoring the changes completely? Which of your clients is going
to thank you for the extra burden?
Finally, anything "manual" can be done wrong. Replicate does it all
automatically!
So What About Unique Keys?
Modern programs should not try to 'molly-coddle' the user in the way that old
programs did. You don't know if the user has four customers called JOHN WARD,
do you?
We recommend that you remove the UNIQUE attribute from almost every key you have.
If you really do need a key to be unique, case number or something, then
you must tell your user to introduce rules where only one site can enter
cases or what have you.
Secondly, to ensure there isn't a clash of your 'invisible, meaningless, primary
key' (remember Dr Codd?), we suggest concatenating the SiteID in front of it:
CUS:ByCustomerID KEY
Containing Fields: SiteID STRING(4) ; CustomerID LONG
Can Replicate Help Network Traffic?
Yes. You see, synchronisation is basically a movement of a 'log' file. A text
file. An XML file actually.
You could set up each machine on a network as another site. Log 'sharing' is done
using Replicate's built-in 'instant' transport system.
What are the advantages?
- Each user runs his own local copy of the program (fast) using his own local data.
A very easy installation. You don't even need to ensure that every user has
the same version of the program as the EXE only 'sees' its own local data
files
- You can take the server down for normal maintenance and all the workstations still
run (off their local data). The users doesn't even know
that the network is down.!
- You have lots of very up-to-date backups.
- Reports run quicker, since all reads (lookups, processes, reports,
browses etc) are local.
- The programs around the network can be different versions. After all,
you can't expect to upgrade all the machines at the same time - and during
a beta cycle you wouldn't want to. (When you do want all the programs to be
the same version, FM2's AutoNet comes into its own).
- File-drivers can be different. You could have a version of your program that runs TPS files
on the laptops and SQL at head-office, for example.
Communication Transports
