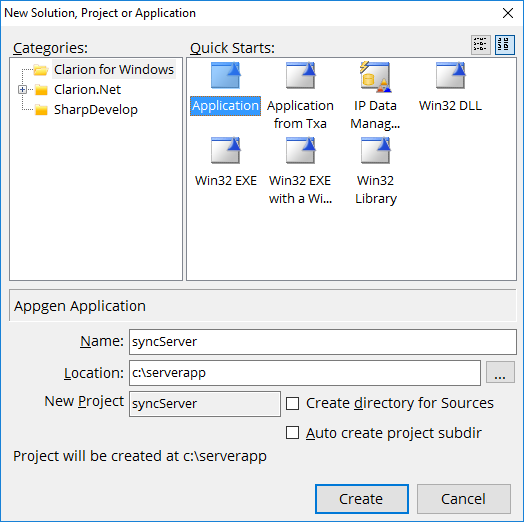
NetTalk Apps is the third level of NetTalk. It
includes all the functionality in NetTalk Desktop and NetTalk Server. In
addition to that it also allows you to create disconnected web
applications and native mobile applications for use on phones and tablets.
To best understand what NetTalk Apps is doing, it's first necessary to
understand a simple premise you have used up to now, and what the limits
of that premise is.
When writing Clarion Desktop (aka Win 32) programs it is understood that
there is one data store. Multiple users can access that data store, but
fundamentally there is a single data store which all users are sharing.
This premise still exists when writing a NetTalk Web application. Many
users sharing one exe, which in turn is sharing one store.
In this context a data store can contain multiple databases, it may be
ISAM (TPS) or SQL based and it may encompass multiple folders on a disk.
But at it's heart the idea is that data is stored in a single place and
(ideally) you don't have the same data stored in multiple places.
Of course data does occasionally need to be replicated into multiple
places, and maintained in multiple databases automatically. This can be
done via replication - either Server-side replication (which requires that
all databases be of the same SQL flavor) or client-side replication (as
with the CapeSoft Replicate extension) which requires that all programs be
written in Clarion.
With NetTalk Apps the goal is to allow different programs with different
data stores, written in different languages, to share data in such a way
that the data can easily flow between many different stores, and
importantly, between many different kinds of stores. The actual storage of
the data, and the capabilities of that storage vessel, cannot be taken for
granted. Data might just as easily reside in an XML file, a SQL database,
a browser's Local Storage or a local ISAM file. The goal is to allow many
different kinds of programs to interact with their own data, and then
share that data with each other.
In some ways this means thinking "beyond SQL". SQL has traditionally been
the store of choice for many programs, and indeed there are many benefits
to having SQL as a store, but data inside a SQL database requires clients
to connect to that database. In order to create disconnected programs we
have to allow the data to escape the SQL database, returning (possibly
changed) at some later point. Of course this does not replace the SQL
database - your primary store will likely remain as a SQL database
(although it could also be TPS) - but rather it expands the horizons of
the database.
Introduction
Before you can start building disconnected apps you
need to understand the concept of distributed data. By definition
disconnected apps keep a copy of the data, and that copy has to be
synchronized with the parent server from time to time. In order for that
to work correctly the tables need to contain specific fields and the
records need to be updated in specific ways.
It should be noted that the mechanism described here is specifically
designed to be completely independent of the data store. If all the
databases were in the same store (like say MS SQL Server) then it would
be possible to use the replication built into that server to do the
necessary synchronization. However as the data will be distributed to
many different platforms (Windows, Web, iOS, Android etc) it is not
possible to ensure that only a single data store is used. Equally this
approach is not limited to any one programming language. NetTalk
contains implementations in Clarion and JavaScript, but the system is
language agnostic and so any program written in any language can join
in, as long as it obeys some rules.
Summary
The logic behind these requirements are discussed
below, but this is the checklist of requirements (for a Clarion app):
- Each table needs a GUID field - type
String(16)
- Each table needs a GuidKey, marked as
unique, on the GUID field.
- Each table needs three TimeStamp fields, all of type Real,
TimeStamp, ServerTimeStamp
and DeletedTimeStamp. These
should have external names of ts, sts and dts respectively.
(NOTE: If using the Firebase backend, uppercase these field names.)
- Each table needs a ServerTimeStampKey
key on the ServerTimeStamp field. The
key is not unique.
- Each table needs a TimeStampKey on
the TimeStamp field. The key is not
unique.
- Whenever a record is updated, TimeStamp must
be set to the current time stamp. In Clarion apps this is usually
done with the NetTalkClientSync global extension
template.
- Whenever a record is updated on the parent server, ServerTimeStamp
must be set to the current time stamp.
Remember the GUID field has
two strict rules.
- The contents of the field must NEVER be
changed.
- Any attempt to populate it using other data should be avoided. It
should contain pure randomized
characters.
Dictionary Fields
GUID Field
This field is required. It is a unique row
identifier. This is (arbitrarily) a 16 character string using a 36
letter alphabet.
Although some databases have a native data type named
Guid
this field should not be native to any specific database. Rather it is
a simple 16 character random string. To make the field both portable
to multiple databases, and easily transportable between databases, it
is recommended that an alphabet of 36 characters (a-z, 0-9) be used.
If considering additional characters in the alphabet:
- Characters > character 127 would render the value not utf-8
(which has transport implications)
- Any punctuation may be a problem with current or future
transport or encoding situations. For example, “ and \ characters
in JSON, < and > in xml and & in HTML
- Whitespace characters (especially tab, cr and lf) may be
incompatible with file formats
- Any control characters (ASCII 0 through 31) should be avoided
- Some systems are case sensitive, others are not, hence either
upper, or lower case letters are preferable
Usually this field forms the primary key for the table if this is a
new table. If another primary key exists then that's ok, but this
field must be unique in the table. Foreign keys in other tables can
use this as the linking key field.
For example:
Invoices Table
Inv:Guid
Line Items Table
Lin:Guid
Lin:InvoiceGuid
The Guid field contents cannot be changed at any
time for any reason.
This avoids the complexity and performance involved in doing related
table changes. It is also necessary for this field to be unchanging in
order to track a specific row through the (disconnected) data stores.
If the Guid field changes, then all other databases are immediately
inconsistent and a consistent state cannot be achieved.
Any attempt to place order on the Guid field, by populating it
with some calculated rather than random field, should be avoided.
Embedding data in the Guid could lead to that data either becoming
inaccurate, or needing to be changed. Additional fields should be
added to the row for storage of additional data. The Guid should
contain completely random values.
Mathematically a 16 character string using an alphabet of 36
characters allows for 36 ^ 16 or 7 958 661 109 946 400 884 391 936
possible identifiers. This can be written as 7.9 * 10
24.
There are approximately (very approximately) 7.5 * 10
18
grains of sand on earth. So a 16 character Guid is sufficient to
identify, uniquely, all the grains of sand on 100 000 planets similar
to Earth. Mathematically, yes, a collision within a single table is
possible,
however it is not
probable.
TimeStamp field
This field is required for all tables that allow
updates in any non-root database. A Real allows for 15 significant
digits. This is sufficient to hold the number of milliseconds since
1970, which is the format used by JavaScript.
ServerTimeStamp field
This field is required. It is a Real holding the
timestamp as last set in the server. On the server this value is
always equal to Timestamp. On the mobile device this value may be
different to Timestamp if the record has been updated on the device.
(The device holds the time of the last update on the device.)
DeletedTimeStamp field
Acts as a deleteflag, and contains the time when
the record was deleted.
CreatedBy field
This field is optional, but can be useful when
distributing a limited data set to other devices. The type is up to
you, but should match an identifier used by your existing users
system. Assuming you have a Users table, and that table has a GUID
identifier, then this field would also be a String(16).
UpdatedBy field
This field is optional, but can be useful when
distributing a limited data set to other devices. The type is up to
you, but should match an identifier used by your existing users
system. Assuming you have a Users table, and that table has a GUID
identifier, then this field would also be a String(16).
Current Time Stamp
While time stamps are necessary in order to compare
records, and choose the later record, the actual measurement of the time
is very arbitrary. In order to provide a generic system, that can be
used across many platforms and programming languages, Unix Epoch time is
used. However Unix Epoch time is typically measured in seconds, whereas
NetTalk allows for milliseconds. If sub-second timings are not required,
or available, then multiply the Epoch time by 1000.
Data is independent of time zone, therefore all time stamps are relative
to UTC regardless of the local time zone where the data is added,
updated or deleted..
The data type used will vary depending on the platform and language. A
type which can contain integer numbers in the range 0-4 000 000 000 000
should be tolerated. (This allows for the system to work until at least
2095.) In Clarion the best type for this is a REAL which easily exceeds
this range.
All NetTalk objects expose a method,
GetElapsedTimeUTC(),
which returns the current time stamp (measured as the number of
milliseconds since Jan 1, 1970.)
Here are some examples;
- Clarion
ts = glo:SyncDesktop.GetElapsedTimeUTC()
- JavaScript
ts = Date.now();
Clarion Dictionary Tips
- Add a Globals data section
- Add a variable, st, to this section.
Set the type to STRINGTHEORY
- Start with one table, and add all the fields (GUID,
TimeStamp etc). You can cut and paste
all the fields from this table to the other tables, so it's worth
getting them perfect before doing that.
- Set the Guid field, Initial Value, to
Glo:st.MakeGuid()
- For the timestamp fields be sure to set the external names (to ts, sts and dts).
- For the Guid and all the TimeStamp fields go to the Options tab
and tick on Do Not Populate.
- For the TimeStamp field go to the Options tab and enter an Option
called TimeStamp, with the value 1. Do the same for the ServerTimeStamp and
DeletedTimeStamp fields, setting their options to ServerTimeStamp
and DeletedTimeStamp respectively.
- Add a Key on the Guid field, a key on the TimeStamp field, and a
key on the ServerTimeStamp field to the table. (At the time of
writing it was not possible to cut & paste keys between tables,
but future versions of Clarion may be able to do that so test to see
if it does.)
Database Field Constraints
It is common in data design to create constraints on
data where one field "must exist" in another table. For example in a
LineItems table you may place a constraint that the InvoiceGuid field
(which identifies the parent invoice record) "Must be in File" for the
Invoice table. Thus creating an explicit constraint that the parent
record (Invoice) has to be added to the database before the child record
in the LineItems table can be added.
Data distribution as described in this document does not make this
constraint impossible, but having this constraint does make the system
more complex and leads to other potential problems. Specifically the
order of table synchronization becomes important, and each table has to
be completely synchronized before another table can be synchronized.
As an aside, in a Clarion application (regardless of backend), the "Must
be in File" constraint slows down the ADD to a child table enormously,
so it's a very expensive constraint there. In a SQL application the
constraint is a lot less costly, but will cause the problems mentioned
above. For this reason it is recommended that this constraint be removed
from systems which support data distribution.
Consistency
Consistency is the concept that all the instances of
the database have the same data.
A disconnected / synchronization system, is by nature not always
consistent. There are times when the mobile device is disconnected from
the network and so has a possibly old version of the database. Since the
program is reading from the local data store the value returned is the
last known correct value, but this may differ from a value elsewhere in
the network.
The system however is eventually consistent. Meaning that once
all data stores have synchronized with the server, they will ultimately
end up with the same version of the data.
Transactions
Consider for a moment the nature of a transaction.
It provides an atomic wrapper around multiple writes to the database,
ensuring that if any write is made, all writes are made and if all
writes cannot be made then none is made.
The key phrase in that sentence is the - as in the database. How then do
transactions occur when the database you are writing to is a local data
store, and not necessarily the main data store? Log based replication
systems are able to support transactions in the sense that the
transaction frame can be written into the log file.
However a disconnected system, such as the one described above,
synchronizes the end result, on a table basis, and does not replay
individual writes, or maintain the order of the writes.
There are fundamentally two kinds of transactions.
- Multiple rows added to one, or more, tables. This is an Insert
transaction - requiring that the whole set of records are inserted,
or non are inserted.
- Data "moved" from one table to another - for example increasing a
running total in one place, with a balancing decrease in a running
total elsewhere. Think of this as an Edit transaction - one or more
records are being edited to maintain some consistent state.
Insert transactions are not a problem. They are added to the local store
using whatever mechanism the local store offers. They can be in one, or
multiple, tables. When synchronizing all the records will be written to
the server.
Edit transactions are more problematic. Consider a common case;
When selling stock of an item, the quantity of the item is set in the
Invoice Line Item, and deducted from the inStock value held in the
Products table.
In this case the inStock value is a running total and every edit or
insert in InvoiceLineItem requires a balancing edit to this value.
This sort of transaction cannot be done in a distributed system, and
indeed running total fields (or calculated fields) of this nature cannot
be maintained using simple data synchronization.
One approach to solving this problem is not to write to the running
total at all at the deice, but rather set the server to update this
total as it updates the lineItems table. In other words move the
maintenance of the running table to the server rather than doing it on
the device.
Another approach is to calculate running totals, rather than storing
them. So, rather than Edit records to indicate a change, Insert a record
to a table so that the change can be recalculated at will.
Auto Numbering
Auto Numbering is a common approach to generating a
unique ID field for each table in a dictionary. In most cases the auto
numbered value is a surrogate value (ie does not correspond to any
actual value in real life - it's just used as a unique ID) although in
some cases it may be a natural value (which has meaning, for example an
Invoice Number.)
Auto Numbered values are usually sequential integers - as each record is
added the next ID is fetched from the server and used as the ID for that
record.
Auto Numbering in order to create a unique identifier has a number of
disadvantages, not least of which is the requirement that there is "one
entity allocating numbers". In a distributed system it therefore cannot
be used as a means to generating primary keys values, since multiple
(distributed) systems can create records at the same time.
Auto Number can still be used for natural values (like invoices) with
the proviso that they can only be allocated when the data reaches the
(single) parent store. So multiple systems could add Invoices (using the
GUID as the primary key) but the actual Invoice Number is only
allocated when the data is synced with the parent store.
Of course since the Auto Numbered value is a natural value, it should
not be used as the linking field to any child tables. The GUID of the
parent table should be used as the linking value.
The majority of requirements for disconnected
applications are the same regardless of whether you are doing disconnected
desktop, web or mobile applications.
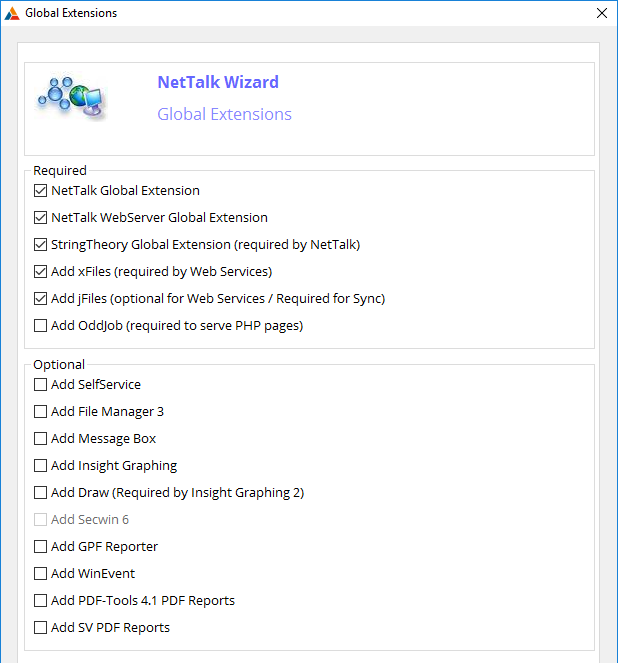
Requirements
The following global templates are required;
- Activate NetTalk Global Extension
- NetTalk Global "Set Time Stamp Fields" template.
- Activate StringTheory Global Extension
- Activate jFiles Global Extension
Field Rules
The fields in dictionary need to be set as follows;
- GUID field
Set to a Random 16 character string when a record is created
- TimeStamp field
Set to the current time stamp when a record is created, updated, or
"deleted".
- ServerTimeStamp field
Unaltered in the desktop program. In the server program (and ONLY
the server program) is set to the current time stamp.
- DeletedTimeStamp field
If a record is "deleted" by a user then the DeletedTimeStamp is set
to the current time stamp. The record is NOT deleted from the table,
it is written to the table as an update. Browses (Reports, Processes
etc) in the table would need to be changed so that records marked as
Deleted are not included in the Browse or Report etc.
Qualifying Tables
In order to be included in a disconnected (web or
mobile) application, the table has to qualify. The following criteria
are used;
- The table has to have a GUID field.
- The table has to have a TimeStamp, ServerTimeStamp and
DeletedTimeStamp field.
- The table does not have the user option
NOSYNC=1
You can also control the specific tables exported in database.js
using the
Tables tab.
Deleted Records
Most of the changes required to turn a "normal"
Clarion ABC application into disconnected desktop application can be
automated. The necessary changes to the timestamp fields and the
changing of a Delete into an Update can be managed by a global template
overriding the File Manager object.
However procedures that read the tables will need to be adapted. The
tables will now contain records which are marked as deleted, and these
records need to be filtered out from browses, reports, processes and so
on where appropriate.
In the case of browses it may be desirable to offer the user a switch to
show, or hide, deleted records - ultimately allowing them to be
undeleted (by setting the deleted time stamp back to 0.)
Unique keys, other than the GuidKey, also need to be considered in the
context of deleted records. For example, if there is a unique key on the
Name column, and a Customer "Bruce" is deleted, then adding another
customer (or the same customer) back with the same name will fail, even
though no customer called "Bruce" appears to be in the table. Adding the
DeletedTimeStamp as an additional component to these unique keys may
suffice as a solution.
Template Support
(ABC)
A Global Extension template, called
NetTalkClientSync
template can be added to ABC applications. If you are making a
disconnected desktop application then you will need to add this template
to the desktop app. If you are creating a disconnected web, or mobile,
application then add this template to the web app. While you do not need
to add it to the SyncServer app, it does no harm to have it in that app,
if that app is shared with say the web app.
This template performs the following chores;
- A global utility object called glo:SyncDesktop
is added to the application. This object can be used to get
the current time stamp. As in;
glo:SyncDesktop.GetElapsedTimeUTC()
- All the time stamp fields are updated appropriately when records
are inserted or updated in any table. This is done in the FileManager
object, so will apply as long as ACCESS:table.INSERT
method is used for adding records (not just a file driver ADD
or APPEND) and ACCESS:table.UPDATE
is used instead of the file driver PUT command.
- When a record is deleted, the DeletedTimeStamp is set, and the
record is updated, not deleted. This works as long as the ACCESS:table.DELETERECORD
method is used and not the file driver DELETE
command.
Apps
Conceptually in any disconnected system there are at
least two parts which need to work together, the client program and the
server program.
In the case of a disconnected desktop system this usually means two
separate apps, a desktop app, and a server app.
In the case of a web (or mobile) program though the server app can
fulfill both the server role, and the client role. In other words in the
web case the server part and the client part can be developed in the
same app file.
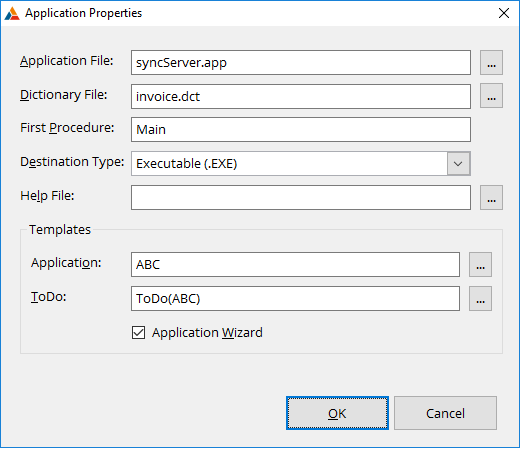
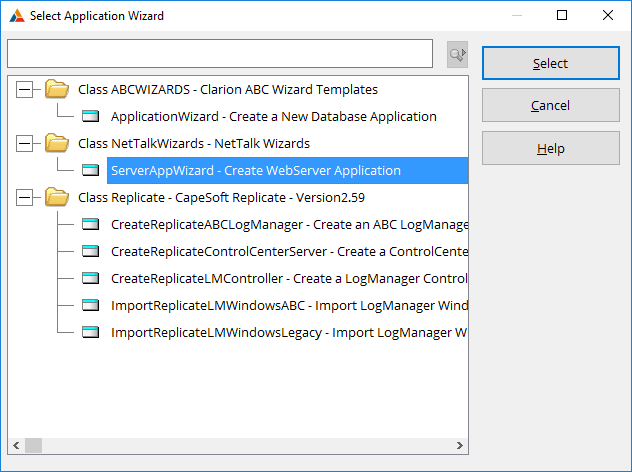
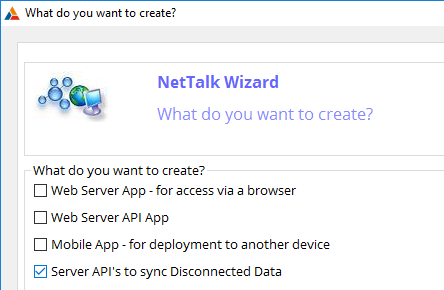
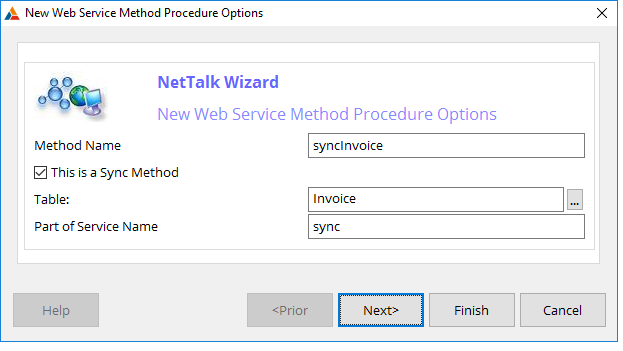
Server App
The server app consists of a single NetWebService
(usually called Sync) and a number of NetWebServiceMethods. Usually
there is a single method for each table in the database. This
application can be generated for you by the NetTalk Wizard. For more
information on generating this application see the section
Server
for Disconnected Apps below.
You can then expand the Server app to include a web-client interface.
This interface can be a normal web app, or a disconnected web app. If a
disconnected web app then it can be packaged as a stand-alone mobile app
as well.
Non-Clarion (or
PROP:SQL) Writes
If the data in the table is edited from a program
not using the NetTalk Client Sync Template, then the rules for updating
the Guid and Timestamp fields MUST be observed. This includes programs
like TopScan, SQL Manager, and PROP:SQL statements that do direct writes
to the database.
Use of this distributed data system specifically does not limit you to
Clarion programs. Any program in any language can read and write to the
data, using any appropriate technique, as long as the field rules are
followed. Some samples of getting the time-stamp value in various
languages are;
Introduction
Disconnected Desktop apps basically have a local
copy of the data. The program itself is written to talk to this local
copy pretty much like any Clarion desktop program would talk to any
database.
Then a "Sync" procedure is added to the local program. This procedure
synchronizes the local data with the remote NetTalk API "Sync" Server.
That Sync Server then interacts with the server-side database.
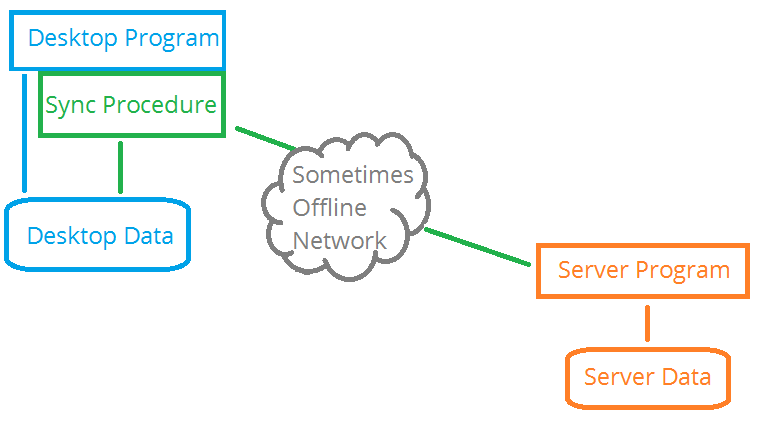
This architecture is useful when the connection between the desktop
program is either too slow, or too unreliable for direct connections to
the main server in the cloud.
The key is in noticing that the desktop program, and the desktop data is
completely unconcerned with the network connection. It is the
responsibility of the sync procedure, which is running in a separate
thread, or even a separate process, to communicate changes with the
parent server, and to get changes made in the parent server back to the
desktop.
This architecture is not limited to a single desktop data set. The
following is also valid
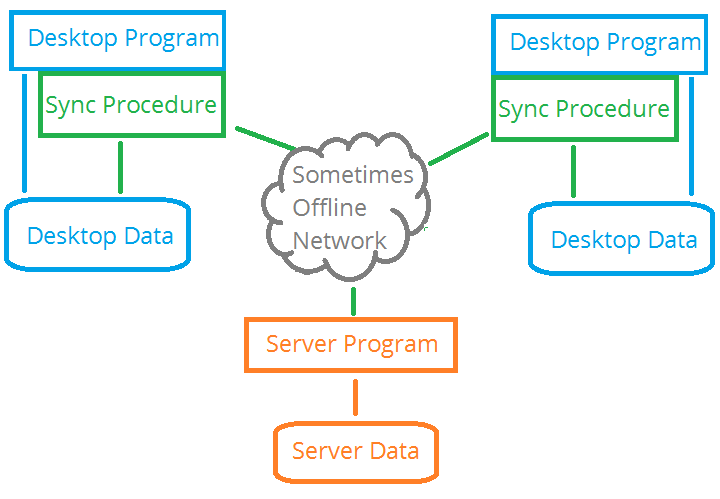
Multiple different locations can synchronize with the same server.
Sync with Server
A Sync procedure can be imported from the example
desktop.app application. This example is in
\clarion\examples\nettalk\apps\DisconnectedDesktop\Desktop\Desktop.app.
In order for data to flow between the desktop app and the server, a
synchronization procedure is required. This procedure can be a
background procedure in your application (ideal where a single user
exists for the remote program) or as a separate program on the LAN. The
sync procedure can be triggered by a timer (every few minutes or so) or
it could be triggered by NetRefresh so that it synchronizes after every
write.
If the desktop is unable to connect to the server then the desktop will
continue working as normal, and the data will then be sync'd on the next
working connection.
The Sync procedure is created as a simple window with the
NetTalkClientSyncControls
Control template added to it. This template requires the
NetTalk
- Set Time Stamp Fields global extension be added to
the application.
The Sync procedure runs on its own thread and can be communicated with
using events. The thread number of the procedure is stored in
glo:SyncDesktop.ControllerThread
A Sync can be triggered at any point, by any thread, by simply posting
Event:SyncNow to the Sync thread. If a Sync is
currently underway then it will complete the current sync and do another
full sync immediately afterwards. For example;
Post(Event:SyncNow,
,glo:SyncDesktop.ControllerThread)
The Sync itself is a fairly cheap operation with minimal overhead, so it
can be called on a regular basis. If no data in a table has been updated
on the server, or client, then it's a very small request and response
for the server.
Note the Sync Procedure will
not create a table on the desktop app if it does not already exist. If
you want the sync procedure to create the table, then add the table to
the data pad for the procedure.
On Delete
As explained earlier, when records are deleted
they are not really deleted, the DeletedTimeStamp
field is just set. This allows the delete to propagate up to
the server when a sync occurs.
By default these records are then left in the local database, as well
as the server database until you do a purge.
The Sync Controls extension template, in the Sync procedure, has an
option to purge deleted records from the client as soon as they are
sync'd with the server. The deleted records will still appear in the
server database as before, but they will no longer appear on the
client. If this option is on then any deleted records sent by the
server to the client will also be immediately removed from the local
database (if they exist) and will not be added if they don't exist.
Sync Procedure Template
Options
The Sync procedure contains a NetTalk - Sync
client tables with server Extension template. The options on that
template are as follows;
Server URL:
The URL of the server that this program will be synchronizing with.
Timer Period
The background timer that determines how often this client connects to
the server. This is a clarion time value, ie hundredths of a second.
The default value of 6000 is 1 minute. This mostly affects fetching
data that has been changed on the server side - data changed on this
client side tends to be sent to the server immediately.
Various Icons
Change the names of the icons if you wish.
UPGRADING: This limits the number
of records that will be sent to the server (or requested from the
server) in a single Synchronization request. Keeping this number small
reduces the memory requirements of the server and the client. A value
of around 500 or less is recommended. If this value is set to 0, then
support for this feature is turned off, and each synchronize will
send, or fetch, all the data that has changed. If this is high number
of records, then this can lead to significant memory consumption on
the server and the client.
If this feature is on then the server has to be set to support it. See
above for
more
information.
Status Field
If you have a string control on the window, which can be used to give
the user updates, then set it here. If this is blank then the
processes will still proceed, but with fewer messages to the user
about what is happening.
Auto Format Fields
If on the fields are formatted, according to their picture, when being
sent.
Purge Deleted Records on Sync
If this is on the the client database will not keep any deleted
records after they have been sent to the server. Deleted records
typically live on the server for a while (so they can be replicated to
other databases) but if this option is on then deleted records are not
stored on the client machine.
Customizing the Sync procedure
Out of the box the Client Sync procedure (usually
called ServerSync) will synchronize all the tables, and rows, in the
local database with the server (for all tables that have the necessary
synchronization fields.)
There are however a number of embed points in the sync procedure where
code can be added to customize the sync.
Inside all embed point the property
self.TableLabel
can be checked to determine which table is currently being
synchronized.
SetJsonProperties
This method provides an opportunity to override,
or set, jFile properties for the outgoing JSON being sent to the
server.
the self.json property contains the
jFiles object.
For example
self.json.SetTagCase(jf:CaseUpper)
CustomData method
The CustomData method
allows you to enter additional JSON fields into the outgoing JSON
collection.
Fields such as token, table
and action are already
included, but this embed allows you to enter additional information
that may be required by your server.
The self.json property contains a
jFiles collection, which you can Append to.
for example;
self.json.append('user','Humperdink')
SetFilter method
When the local data is loaded into the outgoing
JSON a View with a FILTER are used to determine which records are
sent to the server.
A method, called SetFilter, is called
AFTER the filter is set, but before the call to jFiles.append,
to allow you the opportunity to edit the filter.
Use the self.TabelLabel property to
know which table is being exported.
TThis embed allows you to suppress rows in the table which should
not be sent to the server. For example you may choose to exclude all
records from the table where some LocalField is set.
ValidateRecord method
This method is called on both exporting records
to the server and importing records from the server. The properties
self.Importing and self.Exporting
are set appropriately, so test these when importing or exporting.
If you add code to this method it should return one of the following
values;
jf:ok - the record is fine;
jf:Filtered - the record should be
excluded from the import or export.
jf:OutOfRange - the record (and all
subsequent records) should be excluded. This this option very
carefully, especially on import.
FormatValue method
Allows you to format values in outgoing JSON.
Typically this is done for you by the templates (based on pictured
in the dictionary) but you can supplement that, or override it if
you like.
DeformatValue method
Allows you to deformat values in incoming
JSON. Typically this is done for you by the templates (based on
pictured in the dictionary) but you can supplement that, or override
it if you like.
Server-side Filtering
Consider the case where there is one server (with
the complete database of all branches) and several distributed data
sets each with a sub-set of the data (we'll call these "branches" in
this example.)
The goal is allow each branch to receive only the data, and data
updates that apply to this branch. The problem breaks down into two
parts;
- The branch needs to identify itself when doing a sync, and
- The server needs to filter the data based on that ID.
Client Identification
As described above, additional information can
be sent to the server by specifying Custom Data on the client side.
So, in the Desktop program, in the ServerSync procedure, NetTalk
Sync tables with server Extension, Custom Fields tab, add a
parameter name and value.
(Hint: The name should be in quotes)
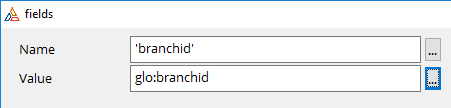
You can name the parameter anything you like, and the value would be
a local, or global variable (or whatever) that identifies this
branch. Keep the name part as a lowercase string.
Server Filter
On the server side, for each Sync procedure that
needs this filter;
- Add a local variable of the same name (branchid
in this example) as is being sent by the client
- Add the variable as a PARMAMETER to the method. You will
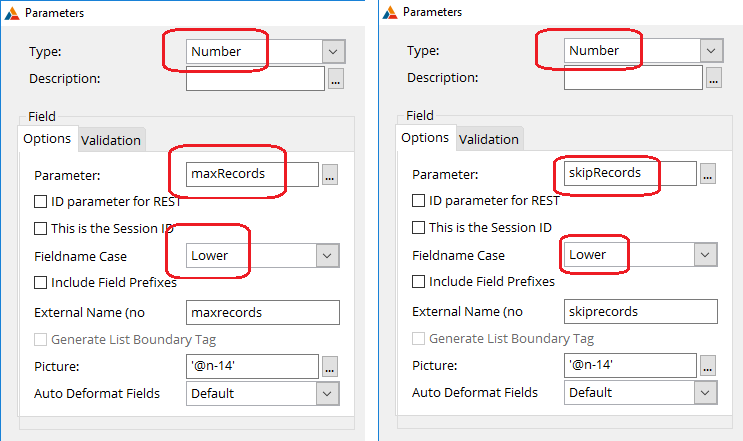
already see other parameters listed there, like maxrecords,
and skiprecords and so on. Add
your variable (branchid) to the
list.
- Use the local variable, branchid,
in your filter.
If the id value is a number then the filter might look like
this;
'cus:branchid = ' & branchid
If the id value is a string then the filter would look something
like this;
'cus:branchid = <39>' &
clip(branchid) & '<39>'
If you have an index (key) on the table, and the key is Not Case
Sensitive then the filter becomes something like this;
'UPPER(cus:branchid) = <39>' &
upper(clip(branchid)) & '<39>'
Introduction
A disconnected web app is a web application where
the browser can be disconnected from the network, but the web app itself
continues to work. In other words a user can go to the web site (say via
a Wi-Fi connection) start working, then walk away, out of Wi-Fi range.
While out of range the app continues to work, and the user can continue
to capture and edit data. Once the user is back in range, and connected
to the server again, then the data is automatically synchronized.
The basic architecture for a disconnected web app is very similar to a
normal web app, however there are some key differences;
- The app is created as a Single Page Application. This means that
the browser will do a single FETCH to the web server, and will
receive the entire application. Supplementary resources (CSS and JS)
are also fetched at this time.
- The app does not interact with the server as the user uses the
system. Rather everything is done on the client, and data is stored
in the browser local storage. This means that embedding Clarion code
in the server is not useful as the server code is not called.
Embedding, where necessary, would need to be done in JavaScript.
- The synchronization of the data requires a Server
for Disconnected Apps. In this server there will typically be
one sync method for each table in the application. Once the web app
is running on the device, the only communication with the server
will be via the Sync methods.
- The Sync methods can be included in the same actual app file as
the Disconnected Web App.
It should be noted that a web app can contain a mix of connected, and
disconnected areas. In other words a single system can contain both a
"normal" web app, as well as one or more "disconnected" apps. This
leads to some flexibility in the way the application is designed.
Supported Browsers
Disconnected Web Apps make use of the HTML 5 feature
called "Local Storage". This allows browsers to store information in a
data store belonging to the browser, which in turn means the app can
work when it is not connected to the network. Local Storage is supported
in all the modern browsers with the notable exception of Opera Mini.
In iOS 5 and iOS 6 it's possible for data in the local storage to be
cleared by the OS, so use of devices running those operating systems is
not recommended.
IE7 and earlier is not supported. Use of any version of IE for
disconnected web apps is not recommended as Local Storage under IE has a
number of different behaviors compared to other browsers.
Task Based Design
Because of the above differences it is very
important that the design of the application be focused around what
tasks the user will need to accomplish when using this app. It is
probable that in many cases only a limited sub-section of functionality
is required by a user when they are disconnected from the network. By
clearly thinking through the tasks which you need to support, you will
better be able to design the appropriate application.
Summary
- Global Extensions, Activate NetTalk Web Server extension, Advanced
tab. Tick on;
Generate for Disconnected App is on.
- Make sure the menu is set so that all the links are opened as
Popup. Links set as Link or Content are allowed, but those links
will not work if the browser is disconnected from the network (ie
cannot access the server.)
Application Cache
The Application Cache Manifest file, while not
absolutely required in order to do web apps, is a way of explicitly
telling the browser which resources will be required by the app. This
feature is supported all major browsers except for IE9 and earlier, and
Opera Mini.
The application cache file is generated into the web folder as app.appcache
where app is replaced by the name of your application. A Manifest
attribute in the HTML of your root page tells the browser of the
appcache file.
You do not need to do anything to turn this support on.
Introduction
Because NetTalk now creates disconnected web
applications, it is possible to take those web applications and
repackage them into a native app format.
For example, using Adobe PhoneGap (which in turn is built on Apache
Cordova), it is possible to wrap the HTML, CSS and JavaScript into a
native application which then uses a native HTML control to show the
HTML to the user. This application contains a mix of native code (eg
ObjectC on iOS or Java on Android) and the HTML you have created. In
addition frameworks like PhoneGap extend the JavaScript language to give
the JavaScript engine access to the native operating system API, which
in turn means you have access to the hardware, contacts list and so on.
Apps built in this way are sometimes know as Hybrid apps, because they
combine the portability of HTML and JavaScript, with a minimal amount of
generic native code to expose the underlying hardware and OS.
The big advantage of this approach is that multiple operating systems
can be supported from a single code base. This makes it ideal for
systems which need a mobile application, but which don't necessarily
have the economic viability of re-coding the same app multiple times
(especially for some of the more minor platforms.)
There are two disadvantages with this approach though. The first is raw
performance. Because the code is HTML and JavaScript it does not have
the raw performance of a native ObjectC or Java program. This makes it
unsuitable for high-performance situations, like games. For data
collection applications though performance is certainly good enough, and
the responses are mostly quite snappy. The second disadvantage is that
the interface can look, and behave differently to a native application.
Using themes and good layout it is possible to mimic functionality to a
high degree, but it will never be 100% the same.
Hybrid apps using PhoneGap can be added to the Apple AppStore but must
still go through the Apple approval process just as any iOS app needs to
do. As such it must conform to Apple's standards for design and
usability. Apps can also be submitted to the Google PlayStore (which has
a much lower set of standards and requirements.)
NetTalk generates the necessary file to make it easy to package the
application using Adobe PhoneGap.
Adobe PhoneGap
PhoneGap is an open source framework, currently
owned by Adobe, which makes it easy to package hybrid applications.
PhoneGap was released under an open source license as Apache Cordova.
the current PhoneGap is an Adobe product, built on top of Cordova, which
encompasses some extra tools.
PhoneGap supports a number of platforms including iOS, Android, Windows
Phone, Blackberry, Bada, Symbian, webOS, Tizen, Ubuntu Touch and Firefox
OS.
Adobe PhoneGap Build
PhoneGap Build is an online platform that allows you
to upload all your HTML, CSS and JavaScript and then does the
heavy-lifting of turning that into a native iOS package or Android SDK.
You don't have to use PhoneGap build, but it is certainly a convenient
and reasonably cheap way to get started. You do not have to use PhoneGap
Build, it is perfectly possible to create your own build environments,
but it is a recommended way to start.
PhoneGap Build supports iOS, Android and Windows 8 as target platforms.
PhoneGap Build requires a configuration file, called config.xml,
which contains information for the build system. This file is generated
for you by mBuild.
NetTalk PhoneGap
Using NetTalk to generate Mobile applications using
PhoneGap is the result of many NetTalk technologies working together.
- The database has to be designed to work is a disconnected way.
- A Server-side API app for synchronizing the data is created.
- A disconnected Web Application is created.
- The resources for the disconnected app are then packaged together
and passed through the PhoneGap Build system. This is done for you
by the mBuild utility.
- The resultant Android APK can then be downloaded and installed on
Android devices. Similarly the iOS build can be installed on iOS
devices and so on.
mBuild
mBuild is a utility that ships with NetTalk Apps. It
does the work of turning your disconnected web application into an APK,
IPA or XAP file. For more on mBuild see the mBuild documentation
here.
Compatibility
The following mobile device requirements are needed
to run NetTalk Apps.
At this stage it's not known that these versions work, however it is
known that versions before this won't work.
More information will be posted here when available.
- IPA File: iOS devices : iOS version 10.3 or later.
- APK File: Android 5 (Lollipop) or later (with Chrome 58 or later
installed)
- Chrome Browser: Version 58 or later
Web-App to Phone-App Checklist
If you have a web app then you can use this list to
set it up to be a phone app ready for mBuild. This is a checklist of
setup items, it doesn't comment on the content of the app itself.
- Adjust the Dictionary to use the table layouts as discussed in Distributed Data Synchronization
above.
- Consider the addition of a Single Record
Settings Table - you'll almost certainly need one.
- Create the Server App.
Make sure this app is served over
HTTPS.
- Go to the Global NetTalk Extension (Activate NetTalk Web Server)
- WebApps tab - Turn Off Pinch To Zoom should be on.
- Apps Tab - Set everything it needs here.
- WebServer procedure - NetTalk extension - Settings / Defaults /
Browse & Form . Layout Method to DIV.
- Create favicon512.png and put into the
\web folder.
- Make sure the Phone app is served
over HTTPS.
- After mBuild runs make sure manifest.json is deployed to the \web folder
Introduction
As the web, and mobile apps, have evolved, so a new
class of application has appeared. The Progressive Web Application is a
web app which conforms to a set of standard behaviors and rules. Once it
does this it can be installed on a phone and will appear to the user as
a native application.
Since we are already creating applications in NetTalk suitable for being
published as a phone app, it is only a short path from there to creating
a PWA. In effect you create your application and can then publish it as
a PWA, Phone app, or (likely) both.
There are a number of advantages of a PWA over a Phone app.
- No approval by any App store
- No need for a user to download the App
- Very easy to roll out updates (since the app effectively checks
for an update on each run.)
Phone apps still have a slight edge in being able to access the native
OS directly and thus access certain things the PWA cannot.
Requirements
In order to be a PWA a web app has to conform to a
number of very specific requirements. The exact list is maintained at
https://developers.google.com/web/progressive-web-apps/checklist#baseline
and could be subject to change in the future.
The key requirements, and how they are managed in NetTalk is listed
below.
| Requirement |
Handling |
| Site is served over HTTPS |
NetTalk can serve HTTPS apps, and with LetsEncrypt support
this process is free of any cost, is easy to do, and is
maintained automatically. |
| Pages are Responsive |
DIV Layout mode for Tables and Forms |
| All App URL's load while Offline |
NetTalk generates a ServiceWorker.Js file into the \web folder
to do this.
(See Global Extension, apps, PWA tab.) |
| Metadata provided for Add to Home screen. |
A manifest.json file is generated by mBuild and needs to be in
the \web folder. |
| First Load fast (even on 3G) |
NetTalk does this for you by implementing several speed
optimizations under the hood. |
| Site works cross-browser. |
NetTalk does this for you. |
| Page transitions don't feel like they block the network. |
The app is a single-Page-Application, so no need for page
transitions. |
| Each Page has a URL |
The app is a single-Page-Application, so there is only the
home URL. |
From the above list you can see that many of these items are a
side-effect of creating a phone app, and so there is no extra work to be
done. There is an extra tab to setup on the global extension, and an
extra tab to be completed in mBuild.
mBuild will generate a
manifest.json
file, this needs to be deployed into the \web folder when you deploy
your web app.
The
manifest.json file will include a
reference to a png file, also in the web folder, called
favicon512.png.
You should create this icon and place it in the web folder. As the name
implies the file is a PNG file, and is 512 x 512 pixels in size. If you
fail to do this the server will serve
defaultfavicon512.png
in its place.
ServiceWorker.js
A new JavaScript file, ServiceWorker.Js is generated
into the web folder. This needs to be deployed along with the rest of
the web folder when deploying the application. This file cannot be moved
into the \web\scripts folder.
Service workers are a special kind of JavaScript that runs in the
browser and acts as a wrapper to the application. Many of the features
necessary to make a PWA happen inside this file. The browser will
aggressively cache this file, so replacing it can be tricky. It
sometimes requires multiple loads of the site, or manual intervention in
the browser developer tools, to refresh this file. Fortunately changes
to this file should not be common.
The service worker also caches a number of other files from your site,
which in turn can have implications when updating static files,
especially js and css files. Be aware that 2 page refreshes may be
necessary to see the latest content.
Chrome, Developer Tools, Audits
The Chrome browser contains a number of features in
the Developer Tools window that make it easier to test and debug PWA
applications. Most specifically an audit tab
is available so a site can be tested to see that it conforms to all the
PWA requirements.
This section covers areas where programming a
disconnected (browser) application differs from a connected web
application.
Database Upgrades
In order to work in an offline state, the
disconnected app makes use of local data storage on the device, which is
then synchronized with the server from time to time. the name of the
storage used is IndexedDB.
IndexedDB has a version number system. Certain types of changes require
that the version number is incremented, whereas other types of changes
do not.
You have 2 options when it comes to setting the dictionary version.
The first option is on the
NetTalk global extension, Activate NetTalk Web Server, Apps / Tables
tab. If the Dictionary Version is set here, to 1 or higher, then this
value is used. If this is set to 0, then this value is not used, and the
second option is used.
The second options is for NetTalk to take the version from the
Dictionary Version number (Dictionary menu, show Properties Dialog).
Adding, or changing fields in a table does not require a version number
change.
Adding, or changing relationships in the dictionary does not require a
version number change.
Adding a table, or a key, does require a dictionary number change. Until
this is done the table, and key, will not be available in the
application on the phone.
Remember - if you add a new table to the dictionary that you wish to use
in the mobile app and you are not including all the tables in the mobile
app, then you will need to add the new table to the
Tables
List as well.
Custom JavaScript File
In a web application it is unnecessary for you to
write custom JavaScript functions as the server is able to let you write
your code in Clarion. In a disconnected application though all the code
has to be written in JavaScript. While the templates will generate most
of what you need, you will almost certainly get to a place where you
want to make some small adjustment or add some code not currently
generated by the templates.
To do this you will need to create a custom JavaScript file, and link
that file into your application. Once that is done you are free to add
to the file whenever you need to.
JavaScript files are simple text files, usually with the extension .js. They belong in your \web\scripts
folder. You can name the file anything you like - something unique and
related to the application is recommended.
Once you have created the file, add it to the WebServer procedure. It is
added on the NetTalk extension, Settings / Scripts tab, in the scripts
list. For now just add the new file to the list, and accept all the
default settings for the file.
Field Priming
The most common use for a JavaScript function is to
prime form fields when a form opens. On the template side NetTalk allows
you to specify an expression for priming fields. You can prime fields on
Insert, Change, Copy and you can also Assign fields on Save.
Since these expressions are language-specific, you will need to enter
either, or both, Clarion and JavaScript values here. Also, the goal is
to keep these expressions as simple as possible, which often results in
a small Clarion Source procedure, or a small JavaScript function being
used.
Some simple JavaScript functions exist in the NetTalk framework which
may help in priming fields; (remember that JavaScript is Case Sensitive)
| Expression |
Description |
| clock(picture) |
Returns the current time, as hh:mm:ss
The picture parameter is not currently used. |
| getUTCTime() |
The number of milliseconds since 1970/01/01: |
| today(picture) |
Returns the current date, formatted using the picture
parameter (which is a Clarion Date Picture). If omitted
then @d1 is used. Supported pictures are @d1, @d6, @d10. |
Note also that the From Location sub-tab (on the Priming tab) can be
used to prime fields with the current Latitude and Longitude. Fields to
receive these values need to be on the firm, but they can be set as
Hidden fields if necessary.
You can also write your own JavaScript function, add it to your
custom.js,
and call it from here.
Assign on Save
The
primeOnSave JavaScript
function is called when the user clicks on the Save button, before the
record is written to the IndexedDB data store. Any code added into
this function by the
template
MUST NOT use any asynchronous functions - in other words it cannot
call any of the IndexedDB methods. If fields need to be primed from
the IndexedDB data store you should do this when the form opens.
Priming from the Local Database on the device
There are some complications which come into
play if you want to prime a field from some other field in the
database.
Firstly, the interaction with the database is asynchronous. So it has
to happen when the form opens, and not as an AssignOnSave. [3]
Secondly you will need to pass something into the form to indicate a
field, either in the parent record, or on the screen, that needs to be
primed.
It is a good idea to pass the form itself to the function as the first
parameter (and then pass more parameters if you like.) The form can be
passed using the parameter this. [4]
So in the template settings the call could be made as
primeSickLeave(this)
or perhaps
primeSickLeave(this,'lea__leavetype') [5]
All of this is best demonstrated with an annotated example;
In this example a default value for Leave Type is being set when the
user wishes to add a Leave record. The default leave type is set with
a field (quicksick) in the leavetype table.
function primeSickLeaveType(form,field){
idbSelect(database,database.leavetype.table,
0,
false,
0,
function(index,record){
if (value.quicksick ==
1){
form.record.leavetypeguid = record.guid
if (field){
$("#" + field).val(record.guid)
}
return
false;
}
return true; // get next
record
},
0, // i
function(){
},
function(event){
console.log('Error
Priming SickLeave record: ' + event.target.error.name + ' ' +
event.target.error.message)
}
)
}
Because the idbSelect call is
asynchronous, functions are passed to the call which execute when a
record is located in the database. This means the field may not be
primed immediately as the form opens, but rather shortly (very
shortly) thereafter.
Notes
1. idbSelect selects the records from a
table. For each record found the onrecord function
is called. If that returns false, then
the result set is terminated.
2. The onrecord function takes 2
parameters, the index in the result set,
and the record itself. All the fields in the table (parameter 2 to
idbSelect) are available, and primed, as a property of the record
parameter. Thus record.guid is the guid field in the result set. Note that at
this point
database.mleavetype.table.record.guid is not set.
3. You may be tempted to use the Assign On Save priming type, and you
can use that for simple functions, however you can't use that for code
which contains asynchronous functions. Since all idb functions are
asynchronous, you are not allowed to use them in code called by
assignOnSave.
4. this is a special word in JavaScript,
which is not unlike the word self in
Clarion.
5. If the field you wish to prime is not on the form itself then you
don't need the second parameter. If the field you wish to prime is on
the form, regardless of whether it is visible or hidden, then pass the
field id (field equate) in as the second parameter. Remember that id's
in JavaScript are case-sensitive and the colon (:) character is
translated into 2 underscores.
Single Record Settings Table
In a web app there are multiple users using the same
server, and so there is typically a record in a user table for each
user. This table contains all the settings for a user.
By contrast, in a disconnected app it is often necessary to have a
"settings" table for the user using that device. This is a single-record
table, and contains important settings which allow the app to work.
Specifically it will likely contain one or more of the URL of the Sync
Server machine, the User name and Password. Since it contains
information needed to connect to the sync server, the Settings form
needs to be functional without a connection to the server.
The application needs to be able to do the following;
- Add a single record to the table if it does not already exist.
- Prime the GUID field in the new record to a unique value.
- Open a form to allow the user to edit the fields in this record
(although the GUID of the record is not known at the time when the
program is generated.)
Fortunately there is template support for a single record table, and
this generates the necessary JavaScript to add the first record for
you. The settings for this is on the Global Extensions, the "second"
NetTalk global extension (Activate NetTalk Web Server), on the Apps /
Settings Table tab. Enter the settings table here, as well as identify
some common fields that might be in your table.
The above template settings take care of the first two requirements
in the list. The last one is done when you open the form. Because the
GUID of the row is unknown, the unique id value can be set to the
special value, _first_. The form will
then understand that you mean to edit the first row (in this case the
only row) in the table.
User Authentication
One of the aspects of App development you will come
across fairly early is identifying, and authenticating, the user who is
using the app. Typically you will want to restrict access to the Web API
to users using your app, or you may want to restrict the data being sent
to the user based on who they are.
There are many ways to approach this, this document shows some possible
methods, but it doesn't cover all the possibilities. Feel free to salt
to taste as required.
The simplest approach is to make use of a Single-Record settings table,
as described
above. Make sure the table
has a field to hold the user name and another field for the password.
Then assign those fields in the global description.
If this is done then those fields are automatically used when making a
sync request to the server. They are used to construct the HTTP
Authentication header, using Basic Authentication. If done over a TLS
(SSL) connection this is safe and secure.
On the server side, the authentication needs to be validated in the
WebHandler procedure, in the Authenticate method. The user name and
password will be passed in there and you can authenticate it there.
Data Type Selection and Transformation
It is common when designing a database to
distinguish between the display of the data and the storage of the data.
For example a date is usually displayed as a string (3 Oct 2016 or
10/03/2016) but stored as a DATE or LONG type.
In order for this to work data has to be transformed when read from the
database before being displayed, and after user entry, it has to be
transformed again before being stored in the database. In Clarion this
happens automatically, based largely on settings set in the dictionary.
Since other languages do not have a dictionary this process becomes very
manual, and has to be applied manually on a field by field basis.
For this reason it is suggested that the storage, and display, of the
data be the same - at least at the mobile app end of things. The server
side can then transform the data as required between a string and a
local data type if desired.
This process is automated by the templates for the DATE and TIME field
types, as well as for LONG fields set in the dictionary with a @D or @T
picture. In these cases the field generated in the JavaScript is a
String, not a number. For the Sync methods on the server the incoming
data is automatically transformed back into the appropriate numeric
(DATE, TIME, LONG) format.
Client-Side Field Validation
In a regular web app field validation is done on the
server. In a disconnected web app (or mobile app) there is no connection
to the server so the validation has to be done on the client
[1].
To make this possible each form field has a validation tab. On this tab
is an option
onchange
[js] which allows you to enter an expression, containing
JavaScript code, which will execute on the client side when the field is
changed. Typically this is a call to a JavaScript function in your
custom.js file.
Note that at this time none of the other Validation settings are
automatically applied to the app. So any, and all, validation must be
done in your custom JavaScript code.
Note 1: Validation still needs to be done
on the server side, in the sync procedure, because data from the client
cannot be trusted. However validating it in the client will help
"honest" users in the sense that their data will not be rejected.
Client-Side Filtering
On the Browse template, Filters tab, there's an
option to set a server-side filter (in Clarion) or a client-side filter
(in JavaScript).
This section describes how local data can be filtered when displaying it
in a local browse.
Note: The easiest way to filter, is not to filter at all. In other words
the need for a client-side filter should be minimal - ideally the device
should only receive the data it needs, by filtering it in the relevant
sync procedure. So if you find yourself "always" filtering, ask yourself
if the data should be on the phone in the first place.
That said, it's not uncommon to filter at least some of the browses on
the device, even when it's reading from local data.
There are some differences to the approach between Clarion and
JavaScript filters though.
First thing to note is that the filter itself is written in JavaScript,
not Clarion code. This would seem to be obvious, but is worth
mentioning.
Second thing is that Clarion filters are designed to be used inside a
VIEW prop:filter, which in turn treats them like a kind of IF statement.
If the statement is true, the record passes.
In JavaScript the code needs to return a value. Permissible values are;
recordOk, recordFiltered
and recordOutOfRange. Remember JavaScript
is case sensitive so these equates need to be used exactly as is. You
don't have to return all these values, any one will do. recordOk
means the record will be included in the result set, recordFiltered
means it will not be included, but reading will continue, recordOutOfRange excludes this record, and any
subsequent records.
In a JavaScript filter the fieldname is prefixed by record.
. This means the "current value in this row" is being compared to
something. for example;
'return record.paid ==1 ? recordOk :
recordFiltered'
In the above expression the value in paid is compared to 1 (in
JavaScript an equals comparison is two = characters). The ? is similar
to a Clarion CHOOSE command - if the
expression is true the first choice is used, if false the second. The
choice are separated by a colon.
The most common filter compares the record to another field on the
screen - presumably where the user has entered a value. For example;
'return record.date >= $("#cloFromDate").val() ?
recordOk : recordFiltered;'
The cloFromDate field is an entry field on
the form. In the above syntax, $("#cloFromDate").val()
returns the current value of the field, as it's seen on the
screen. Since the filter is inside single quotes (because on the server
side it is treated as an expression - a string - it is handy to use
double quotes when needing to quote things in the actual JavaScript.
The record prefix only applies to the primary table in the browse. If
you wish to test the value of any secondary table fields then you must
use the full database.tablename.record
prefix there. Table names are always in lowercase. For example;
'return (record.date >= $("#cloFromDate").val()
&& database.leave.record.approved > 0)? recordOk :
recordFiltered;'
Given that the filter is a function you can write a custom function in
your custom.js file and call it from here
as well. Just be sure to return one of the values specified above.
A general discussion of the JavaScript language is
beyond the scope of this documentation, however there are some useful tips
around the specific NetTalk JavaScript which may be useful here.
Database.js
Note: As from build 9.18 the resultset
property has been removed. Functions using resultset
(idbSelect, idbSummary) should pass in a resultset parameter array
instead.
The tables from your dictionary, and a number of helper functions, are
generated into scripts/database.js. This
file contains the table structures, as well as other information for
each table. It also contains a number of properties for the database
itself.
A global object called database is
declared.
This contains a number of properties (such as synchost, user, password,
and so on.) You can use these properties in your own code if you need
to. For example;
var user = database.user;
It also contains an array of tables. One item in the array for each
table used by your application. As it is an array each table has a
number, but this number could potentially change if new tables are added
to the system. Each table also has a name, and you can reference a table
using this if you like. For example;
var sometable = database.tables[0]
JavaScript arrays are base 0.
Here's an example of code to loop through all the tables;
var j = 0;
for (j in database.tables){
if(database.tables[j].name == 'customer'){
sometable =
database.tables[j];
}
}
To make things a bit easier an alternate name is generated for you.
Instead of referring to the table by its number in the array, you can
refer to it by name. For example, for a table called customers;
sometable = database.customers.table;
As you can see this is the simplest approach if you are accessing a
single table with a known name.
Each table has a number of properties (name, keys, relations and so on)
but importantly it also has a record. This contains the individual
fields that make up the data area of the table. For example;
somename =
database.customers.table.record.firstname;
This can be shortened a bit to
somename = database.customers.record.firstname;
The record structure contains a single record in the table. This
structure needs to be populated before any record is written to the
table (using idbOne, idbWrite, idbAdd, idbPut,
idbMarkDelete or idbDelete).
When reading a single record (idbGet) then
the record is populated with the result of the read. If the record is
not located then the record is unaltered.
When reading a group of records (idbSelect),
an a onRecord function is used, then the
record structure is populated on each call to onRecord. If an onRecord
function is not used, then the record structure is not primed,
but all the records are instead sent to the resultset
parameter. For example;
Calls to idbSelect which do not pass an onRecord function will have the result sent to
the oncomplete function. You can then loop through the result set,
inspecting each record as you go.
You can iterate through the result set;
var row=0;
for (row in resultset){
database.customers.record = resultset[row];
// do something here
}
Two utility functions are also provided. These are mostly used for
debugging purposes.
database.tablename.view()
This sends the contents of the table to the browser debugging console as
a pipe separated list. This allows you to see the number of records in
the table, and also the contents of the table. You can use this function
directly in the browser developer tools area.
database.tablename.empty()
As the name suggests this empties the table in the browser. Again, this
is mostly useful for debugging purposes.
This will drive you insane: Bear in
mind that if you are sync'ing data with a server then the data in the
server will be re-fetched on the next sync. So if you empty the table
locally either empty it on the server as well, or be prepared for the
data to re-appear.
nt-idb.js
The reading and writing to the local data is done
with a set of NetTalk JavaScript functions. These functions are located
in scripts\nt-idb.js. If you wish to access the data directly from your
own JavaScript code then you will want to make use of these functions,
so they are documented here.